【85 頁】
消費者セグメント毎に軸の重要度が変化するジョイント・スペースを持つブランド選択モデル
杉田 善弘
1 はじめに
自社ブランドの市場での消費者による評価とライバルとの競合状況を知ることは重要である。また,消費者のブランド・ロイヤルティーは強いのか,値引きされたブランドばかりを狙って購買するブランド・スイッチャーは市場にどの位存在しているのかなどの情報も必要であろう。さらに,市場にどのような消費者セグメントが存在し,そこでのライバルとの競合状況を把握する必要もある。特に,ブランドの担当者にとって重要なのは,このような事柄について勘や主観ではなく,現実のデータに基づいた客観的な知見を持つことである。
杉田(2011)は,ブランドに対する消費者の評価と競合状況を把握するために用いるのに便利な改良された消費者ブランド選択モデルを提案し,実際のデータを用いてモデルを検証し,おおむね満足の行く結果を得た。杉田(2011)のモデルは,一般的なブランド選択モデルにジョイント・スペース(それぞれの次元が消費者のブランド選択の基準である多次元(軸)上でのブランドの位置(ブランド・イメージ),いわゆるプロダクト・マップと消費者がそれぞれの次元で理想とする位置である,アイデアル・ポイント(理想点))を導入し,ブランドの競合状況と家計の選好を把握するためのものである。このモデルのオリジナリティーは,アイデアル・ポイントが過去の複数の購買(購買履歴)に依存して,家計毎にダイナミックに変化することと,理想点以外にも存在するであろう家計の異質性をモデル化したことである。つまり,理想点の違いだけでは捉えられない異質性,たとえば,消費者の価格に対する反応の違いもモデル化したのである。
本研究の目的は,この杉田モデル(2011)をさらに改良し,ブランド選択の基礎となる多次元のイメージ軸の重要度が消費者毎に異なると考えたモデルの構築である。たとえば,トヨタ自動車のクラウンと日産自動車のフーガのイメージを考えよう。どちらもそれぞれの企業を代表するセダンで,仮にイメージ軸にはスポーティーさと車格という二つの軸があるとする。消費者Aはスポーティーという軸に重きを置いて考え,この軸で理想に近い車を求め,消費者Bは車格という軸に重きを置いて,この軸で理想的な車を求めるかもしれない。
本論文のこれからの構成は次のようなものである。まず,実際の購買データからジョイント・スペースを構築することによって,ブランドの競合状況と消費者の選好を明らかにしようとするモデルの展開をレビューする。そして,本研究で提案されるモデルを紹介し,モデルを
【86
頁】
スキャンパネル・データに適用した結果を報告する。最後に,今後の課題について議論する。
2 ジョイント・スペースによるブランド選択の分析
2.1 ジョイント・スペース・マップ
ひとつの市場で競合している製品のポジショニングを多次元上でデータから統計的に再現したものを知覚マップという。通常はマップを理解しやすくするために,次元は2次元で,製品は地図上の点として表され,それぞれの軸は消費者が製品を知覚(イメージ)するための基準と考えられる。知覚マップ上で,どの製品が消費者に好かれるか(消費者の選好)は製品の位置からだけではわからない。知覚と選好は別のものだからである。ある商品を高級品と考えることと高級品にニーズがあることとは別である。ここで,消費者の選好を特定できれば,消費者に好かれる良い位置を知ることができる。選好をデータから特定することは選好分析と呼ばれ,そのためにはふたつの方法が用いられる。ひとつは,マップ上で消費者にとっての理想の位置を特定することである。もうひとつは,マップ上で消費者にとって製品の価値が増す方向を特定することである。この方向は矢印としてあらわすので,アイデアル・ベクトルと呼ばれる。また,理想の位置はアイデアル・ポイントと呼ばれる。知覚マップと選好分析は,まずマップを作り,そのあと選好分析を行うというように段階的に行われる場合もあれば,同時に行われる場合もある。段階的に行われる場合の選好分析は選好の外的分析と言われ,同時に行われる場合は選好の内的分析と呼ばれる。消費者の選好(アイデアル・ベクトルあるいはアイデアル・ポイント)と知覚を同時に描いたものがジョイント・スペース・マップである。
実際にマップを作るためのデータとして多く用いられるのが,アンケート・データを用いる方法である。しかし,この方法は,消費者の記憶にある知識や考えを基にしたもので,実際の購買行動から得られたものではない。消費者の記憶や考えと実際の行動が一致しないことはマーケティングでは良く知られている。そこで,近年,家計毎の実際の購買データであるスキャンパネル・データから,選好の内的分析によるジョイント・スペース・マップそして価格などのマーケティング・ミックス変数への反応を同時に得ようとする本稿で扱うブランド選択モデルが提案されてきた。マーケティング変数が観測されたスキャンパネル・データを用いて,これらの変数の効果を織り込んでマップを作れば,マーケティング変数の影響を排除し,しかも消費者の実際の行動を基にしたジョイント・スペース・マップを作ることができる。
ここで問題になるのは,消費者のイメージにも選好にも個人差があり,本来ならジョイント・スペース・マップは消費者の数だけあるはずだということである。それでは,知覚も選好も多数になりすぎて,マップから戦略的示唆を得るのが逆に難しくなる。そこで,消費者間の知覚の差はさほど大きくないが,選好の差は大きいと考えて,マップは全体でひとつということにして,選好の異質性を何らかの形でモデル化するのが普通である。つまり,高級な車は誰が見ても高級だが,高級な車が好きかどうかは大きく違うと考えるということである。さらにスキャンパネル・データは,普通一度しか行わないアンケートと異なり,家計の購買を経時的に把握しているという特徴があり,消費者の知覚と選好は時間的に常に安定しているわけではないということも考慮することができる。ここでも,知覚はデータの期間が1〜2年と比較的短いこともあり,安定していると仮定するのが通常である。選好は,過去の購買経験による家計の好みの変化を反映するブランド・ロイヤルティー変数がモデルのフィットを大きく改善す
【87
頁】
ることからも,消費者の好みは変化していると考えられ,そのことをマップに反映させるのである。
2.2 ジョイント・スペースとマーケティング変数を組み込んだブランド選択モデル
ジョイント・スペースとマーケティング変数を組み込んだブランド選択モデルの基本となるモデルを紹介しよう。このモデルでは,家計が各ブランドに対して感じる効用は,確定的効用(ブランドの布置とアイデアル・ベクトルまたはアイデアル・ポイントとマーケティング変数によって定まる)と誤差項に依存すると仮定する。誤差項は消費者の心の揺れなどのランダムに変化する部分で,確率的に変化すると考える。逆に,ブランドの布置とアイデアル・ベクトルまたはアイデアル・ポイントによるジョイント・スペースとマーケティング変数の部分は消費者毎に確定するので確定的効用と呼ばれる。誤差項の確率分布が第2種の極値分布であらわされる場合は,以下のようなマーケティング・サイエンスで人気が高いロジット・モデルによって定式化され,ブランド選択確率は確定的効用に比例する。
![]()
ただし,h=家計,j=ブランド゙,t=期
確定的効用をジョイント・スペースからの効用とマーケティング変数からの効用に分けて表すとブランドの効用は次のようになる。
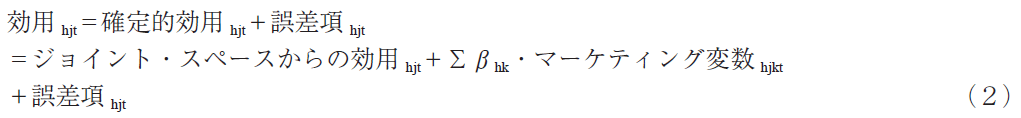
k=k番目のマーケティング変数,βhk=家計hにとってのマーケティング変数 k の重要度。マーケティング変数は複数あっても良い。
ここで,ジョイント・スペースからの効用はアイデアル・ベクトル・モデルの場合,
![]()
ただし,m=m番目の軸,一般には軸の総数は2,軸の重要度hmt =家計hにとっての軸mの購買機会tでの重要度,布置jm= m軸でのブランド j の布置。
となり,アイデアル・ポイント・モデルで表すと,
![]()
ただし,アイデアル・ポイントhmt=購買機会 tでの家計hにとってのm軸上でのアイデアル・ポイント。
アイデアル・ベクトル・モデルでは,それぞれの軸の重要度(負の符号を持つこともある)と各軸でのブランドの布置の積の和でブランドの価値が決定されるので,重要度と布置の積が
【88
頁】
正で大きいブランドほどブランドの価値が高くなり,選択される確率が大きくなるということである。ここで,注意を要するのは,軸の重要度には家計を示す添え字がついていることとブランドの布置には家計の添え字がないことである。つまり,軸の重要度は家計固有であるが,布置は全家計共通であることを示している。軸の数が2になっているのは,3次元以上ではマップが見にくいという理由である。このモデルにはマーケティング変数の効果も組み入れられており,例えば,商品が選択される可能性が高いのは安売りによるものかブランド価値によるものかを知ることができる。そしてマーケティング変数 k の重要度を示す,βhkにも家計を示す添え字 h がついていて重要度は家計ごとに違うことを示している。
アイデアル・ポイント・モデルでは,ブランドの布置と理想点との距離が少ないほうが効用を大きいと考えるので,ブランドの布置と理想点との距離であるΣ(布置jm−アイデアル・ポイントhmt)2には負の符号がついている。さらに,アイデアル・ポイントには,家計を示す添え字がついている。つまり,アイデアル・ポイントは家計に固有であるが,布置は全家計共通であることを示している。
この二つの基本モデルからは,マーケティング変数の効果を除去したブランド価値の構造を理解することができる知覚マップが得られ,ブランド価値を形作る基準とその重要度あるいは理想点,マーケティング・ミックスへの反応とこれらの家計間での異質性を理解することが出来る。
これまでに提案されたモデルの違いは,基本モデルの長所をどう生かし,問題点をどのように扱うかである。特に,最近の多くのモデルが工夫しているのが,状況依存性と家計の異質性の取り扱いである。表1は,スキャンパネル・データとブランド選択モデルを用いて,選好の内的分析を行うモデルを五つの視点からレビューしたものである。五つの視点とは,アイデアル・ベクトル・モデルかアイデアル・ポイント・モデルかということ(モデル),消費者ニーズを前回購買ブランドというような状況に依存させているかということ(状況依存性),軸の重要度を考慮しているかということ(軸の重要度),マーケティング変数への反応を測定しているかということ(マーケティング変数),家計の異質性をどう取り扱っているかこと(観測できない異質性)である。

【89 頁】

表1からも分かるようにアイデアル・ベクトルとアイデアル・ポイントの人気は拮抗しており,二つのモデルを比べたElrod(1991)や筆者の研究でもアイデアル・ポイントを用いた方がデータへの適合度は少し優れているが,大きな差はない。ここでのモデル群の大きな違いは,アイデアル・ベクトル・モデルでは軸の重要度が用いられ,消費者がどの軸にも同じ重みを与えているとは限らないということが認識されているが,アイデアル・ポイント・モデルでは軸の重要度が用いられたモデルはないということである。
状況依存性というのは,同じブランド選択といっても消費者が直面している状況によってニーズが変化すると考えるもので,表1からも新しいモデルほど状況依存性をモデル化しているのが分かる。ブランド選択に関するデータを時系列でみることができるスキャンパネル・データを分析するモデル群なので,状況依存性と言うと,購買経験をモデル化することが多い。Erdem(1996)とInman et. al.(2008)は前回購買されたブランドの影響を前回購買ブランド・ダミー変数を用いてモデル化している。Lee et. al.(2002),里村(2004)そして長谷川(2011)は前回購買機会から一定の確率で変化,つまりマルコフ過程にしたがうニーズをモデル化している。杉田(2011)のモデルは前回購買だけではなく,過去の多くの購買経験に依存して変化するアイデアル・ポイント・モデルを構築した。土田(2009)は購買経験より一般的な購入オケージョン(時間帯と場所)によって,状況依存性を捕らえた。
これらの実際の購買履歴からブランド選択モデルを用いて作ったマップの特徴の一つは,マーケティング変数の効果を取り除いたマップを作ることであるが,Lee et. al.(2002)と土田(2009)のモデル以外はマーケティング変数をモデルに含包している。
ここで観測できない異質性というのは,家計のデモグラフィック特性のように変数として観測できるばらつきではなく,アイデアル・ベクトル(ポイント)やマーケティング変数への反応度のように推定しなくてはならないパラメターの家計間でのばらつきをいう。たとえば,アイデアル・ポイントは全家計で同一と考えるよりも家計間にばらつきがあると考える方が自然である。家計間の観測できない異質性の存在をモデル化しないと分析結果に偏りがおきるし,観測できない異質性はセグメンテーションや個々の家計への対応というように実際マーケティングを行う上でも非常に重要である。
この異質性に対処するためには,面倒でも個々の家計ごとに推定をすれば良いのだが,いくらスキャンパネル・データといってもそれぞれの家計について,ひとつの商品の購買データが100もあるわけではない。商品にもよるが,1週間に一度買われる商品でも100のデータが揃うには2年間かかる。この問題の一般的な解決策としては,パラメターの家計間でのばらつきに関して特定の分布を仮定するという方法が取られてきた。つまり,パラメターのばらつきが正規分布にしたがうなどと仮定する。こうすれば,パラメターの分布を用いて家計をプールすることができ,個々の家計のデータ不足を補うことができるからである。と言っても,1990年代初めまでは,仮定された分布の特性値(期待と分散)を求めるだけであったが,それ以降は連
【90
頁】
続的に値が分布する正規分布を仮定して,ベイズ統計の手法によって家計別パラメターを推定する方法とパラメターがいくつかの離れた値(この値をクラスという)に集まる離散分布を仮定して潜在クラス分析によって家計のそれぞれのクラスへの所属確率を推定する二つのやり方が主流となった。潜在クラス分析でのクラスがマーケティングでのセグメントと考えられる。
異質性への対処から見ていくと,初期のモデルであるElrod(1989)とErdem(1996)のモデルは,連続分布を仮定して,特性値を求めた。片平(1990)のモデルは潜在クラス分析を用いない方法でマーケット・セグメントへの所属確率を計算する独自の方法を提案した。Inmanet. al.(2008)と杉田(2011)は潜在クラスモデルを用い,各家計のセグメントへの所属確率を推定した。里村(2004)と長谷川(2011)はどちらもベイズ統計の手法を用いて,前回購買機会に依存してアイデアル・ベクトルがマルコフ過程にしたがうとしたモデルを推定した。
パラメターの異質性に対処するための方法として,連続分布を仮定したベイズ統計と離散分布を仮定した潜在クラス分布のどちらがすぐれているかは判断が難しい。ベイズ統計のほうが良いとする研究(Allenby and Rossi 1999)もあれば,ベイズ統計はパラメターの推定に使われたデータにはより良く当てはまるが,家計毎のサンプル数が小さい場合,予測と推定値の誤差では潜在クラスに劣るとする論文(Andrews et. al. 2002)もあるからである。次節では,軸の重要度の家計間異質性を考慮した本論文の提案モデルを紹介しよう。
3 ダイナミックに変化するアイデアル・ポイントと軸の重要度のセグメント間の異質性を考慮したブランド選択モデル
3.1 モデルの構造
本論文の提案モデルは,家計の持つアイデアル・ポイントは過去の多くの購買経験に影響されうると考えたジョイント・スペース・マップ,マーケティング変数の効果そしてマーケット・セグメントごとに異なる軸の重要度を考慮したブランド選択モデルである。このモデルの選択確率に関する式は基本モデルと同じであり,選択確率はロジット・モデル(式1)で与えられ,効用はアイデアル・ポイント・モデルを持つ式(3)に軸の重要度を付け加えた式(4)で表される。
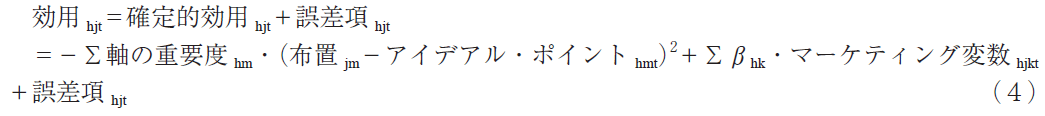
ただし,軸の重要度hm=家計h にとってのm 軸の重要度>0。
このモデルの最大の特徴は,軸の重要度が家計によって異なる可能性を考慮したアイデアル・ポイント・モデルであるということで,日産のフーガとトヨタのクラウンの例のように,家計によってイメージ軸の効用への寄与度が異なる可能性を認識している。式(4)は次のようにスケールを変えた,重要度を考慮しないアイデアル・ポイント・モデルとして書き換えることが出来る。
![]()
【91 頁】
![]()
ただし,布置*jhm=(軸の重要度hm)0.5・布置jm,アイデアル・ポイント*hmt=(軸の重要度hm)0.5・アイデアル・ポイントhmtである。
ここから分かるように,軸の重要度が全家計で同一の場合は,軸の重要度をもうひとつのパラメターとして扱うことの意味はない。軸の重要度を持ったアイデアル・ポイント・モデルは,家計の異質性を推定することが出来るベイズ統計や潜在クラス・モデルなどによって始めて推定可能となるモデルである。式(4)からも分かるように,このモデルでは,各軸からもたらされる効用は,その軸でのブランドの布置と理想点の距離と比例して大きくなる不効用(嫌いさの度合=ペナルティー)という形でモデル化されるので,ブランドと理想点の距離が同じでも,軸の重要度が高ければ,その軸からもたらされる不効用は高くなる。逆に,重要度が低ければ,ペナルティーは小さい。したがって,相対的に重要度が高い軸が不効用に占める比率は高くなり,その軸での優劣が選択確率に大きく影響する。
相対的に,どちらの軸が重要かということに加えて,それぞれの軸の重要度の絶対的な大きさも大切である。各軸の重要度が低いと,ブランドの効用は(各軸での不効用が小さくなるので)高くなる。つまり,このモデルでは,重要度が低いことは,商品への評価が低いこととは必ずしも一致しない。ただし,重要度が低いと,どのブランドについてもペナルティーが小さいので,選択確率は平均化される傾向になる。
このモデルのもう一つの特徴は,杉田(2011)モデルと同様に多くの購買経験を反映したアイデアル・ポイントである。つまり,家計は前回のみではなくそれより以前の購買による経験も覚えていて,ニーズに多くの購買経験が反映されている可能性が高いということである。それではこのような場合にアイデアル・ポイントをどのように決定すれば良いのだろうか。ある家計がひとつのブランドのみを購買しているのであれば,そのブランドの位置とアイデアル・ポイントは一致していると考えて良い。もしふたつのブランドを半分ずつ購買しているので,ブランド・シェアが同一であれば,アイデアル・ポイントはふたつのブランドの位置の平均である中間に位置していると考えるのが普通であろう。下の表2は,ふたつの家計A,Bどちらもが,ふたつのブランドを購買していると仮定した購買機会毎の架空のブランド選択を表にしたものである。

どちらの家計もふたつのブランドを半分ずつ購買し,ブランド・シェアは各ブランド50%で同一であるが,家計Aはふたつのブランドをスイッチングしながら購買し,家計Bは最近3回ブランド2を購買している。この場合,家計Aのアイデアル・ポイントはふたつのブランドの中間にあり,家計Bのアイデアル・ポイントの方は,最近ブランド2を続けて購買しているので,ブランド2の位置にぐっと近づいていると可能性が高いと考えるのが自然であろう。つま
【92
頁】
り,家計内ブランド・シェアが同じ値(ここでは,50%)でも,購買履歴によって,アイデアル・ポイントの位置は異なると考えるのがより自然であり,これがダイナミックに変化するアイデアル・ポイントという考え方である。
このために,本提案モデルで用いられるのは,Guadagni and Little(1983)のブランド・ロイヤルティー変数として知られる,購買履歴を単純なブランド・シェアより良く表現できる加重平均である。
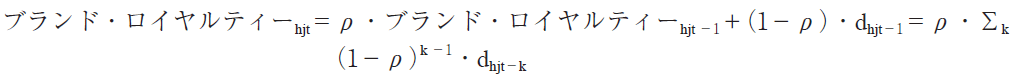
ただし,dhjt−1=前回ブランド j が購買されれば1,されなければ0のダミー変数,ρ=記憶パラメター,0≦ρ≦1
ブランド・ロイヤルティーは過去すべての購買の加重和であり,重みは前回購買が一番高く,ρで,一回遡るにつれ忘却のため,(1−ρ)ずつ減っていくのである。そしてアイデアル・ポイントをこの変数によって重み付けられたブランドの布置の加重平均と考えればよい。
![]()
表2の場合,家計Aの購買は,記憶パラメターであるρを大きくすれば,過去の多くの購買に重みをつけることになるので,ブランド・ロイヤルティー変数の値はブランド・シェアに近づき,ブランド・スイッチャーであることがうまく表現できるようになる。つまり,ブランド・スイッチャーの理想点は,直前に買ったブランドの位置へ大きく近づくことはなく,過去買ったいろいろなブランドに関する経験が少しずつ影響し,購買したブランドの布置の中間的な位置をとる。逆に,家計Bの購買は,ρが小さくなると最近の購買により多く重みがつくので,理想点は一定のブランドの方向へ大きく動き,ロイヤルティーをうまく表現することができる。また,このモデルでは,記憶パラメター(ρ)は軸毎に異なると考える。つまり,家計は軸毎にブランドに対して,ロイヤルであったり,スイッチャーであったりする可能性を持つ。さらに,家計が持つパラメターの異質性に対処するために,ブランドの布置以外のパラメターである軸の重要度,記憶パラメター(ρ)そしてマーケティング変数の重要度の異質性を潜在クラス・モデルによってモデル化する。そこで,市場には,S 個のそれぞれの軸の重要度,記憶パラメター(ρ)とマーケティング変数の重要度を持つ(いわゆるベネフィット・)セグメントが存在し,家計はこれらのセグメントのいずれかに,データ期間を通して,一定の確率で所属すると仮定する。軸の重要度とρは軸毎に異なるので,それぞれS×次元数だけある。また,ρが異なるので,結果として,アイデアル・ポイントもセグメントごとに異なる。セグメント s に所属する家計 h のブランド選択確率は次のようになる。
![]()
ただし,h=家計,i, j=ブランド,t=期,s=セグメント。
![]()
【93 頁】

ただし,m=軸,m=2 とする,k=k 番目のマーケティング変数。
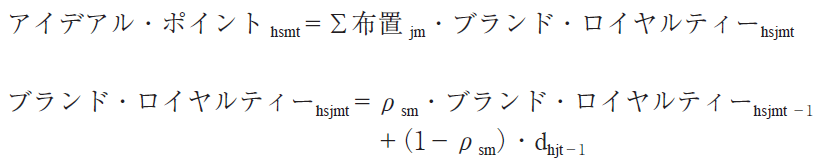
ブランドの布置は,他のモデルと同様に,状況の如何やセグメントにかかわらず一定であると仮定する。家計はセグメント s に次のような確率で所属する。
セグメント所属確率 hs=exp{セグメント s に固有の定数}/Σexp{セグメント q に固有の定数}
それぞれのセグメントに固有の定数は家計がそのセグメントに全購買を通じて所属する可能性を表現している。
3.2 データ
分析に用いたデータは,食料品のパッケージ財1カテゴリーに関するスキャンパネル・データ1)で,70家計の5ブランドの購入に関するもので,全購買回数は742回2)である。ブランドの詳細は表3の通りである。
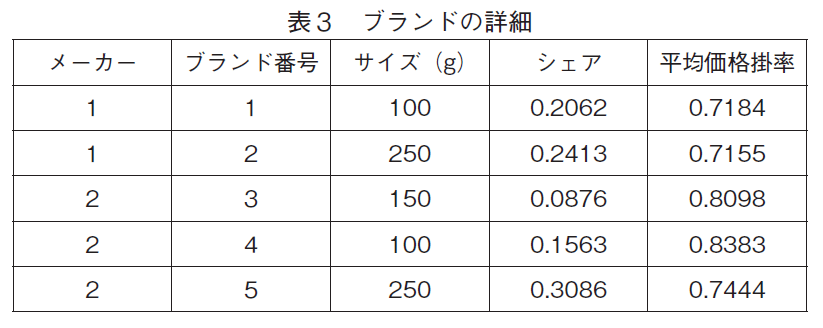
この製品カテゴリーには,他にも多くのブランドが存在するが,この2メーカーの5ブランドで市場全体の売上の多くを占めている。表3のシェアは,これらの5ブランドの中でのシェアを示している。表中で最もシェアが高いのが番号5のブランド(以下ブランド5と呼ぶ,その他のブランドも同様)で,シェアは約30%である。次に,シェアが高いのはブランド2であ
【94
頁】
り,約24%のシェアを持っている。しかし,ブランド3とブランド4の違いはサイズだけであり3),この両者を合わせると,こちらも24%ほどのシェアを持っている。一番シェアが低いブランド1でも,シェアは20%以上あるので,シェアから見れば,この5ブランドはかなり拮抗した競争をしている。
ブランド2とブランド5は,同じ製法で作られていて,メーカーによって普及ブランドと位置づけられている。これに対して,ブランド1,3,4は,ブランド2,5とは違う同一の製法で作られ,プレミアム・ブランドとして位置づけられている。実際売価の標準価格に対する比率である価格掛率4)を見ると,平均ではブランド1,ブランド2,ブランド5の掛率が低いが,平均だけでは読み取れないそれぞれのブランドの価格戦略が存在しているようである。
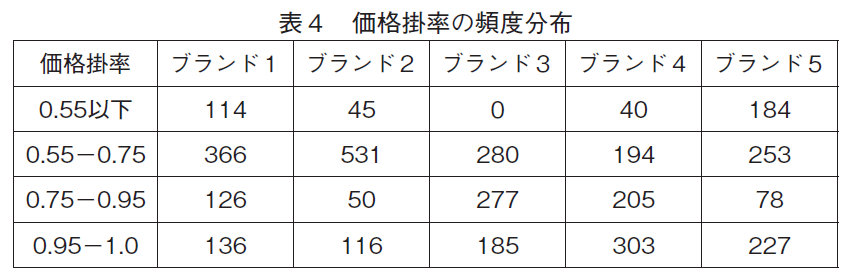
表4は価格掛率の頻度分布である。ブランド1と5はほぼ標準価格(掛率が0.95−1.0)で売られていることも多いが,安い価格帯,特に標準価格の半値近く(掛率が0.55以下)で売られていることも多い。逆に,ブランド2は,ブランド1やブランド5ほど極端に安い価格帯では売られることは少ないが,安い価格帯(掛率が0.55−0.75)で安定的に売られていることが多い。ブランド3と4は他のブランドに比べ,標準価格近辺(掛率が0.75−1.0)で売られることが多く,値引きはそれほど極端ではなく,価格は安定しているようである。
3.3 結果
このデータに対して価格掛率をマーケティング変数として持った本研究の提案モデルを適用して最尤推定した。推定には,購買回数が少ない4家計は除き,66家計のデータを用いた。まず,提案モデルについて,セグメント数が2から始めて,複数のセグメントを持つモデルを推定し,結果を比較して最良のセグメント数を決定した。セグメント数が1の場合は,軸の重要度パラメターは冗長なので,提案モデルは杉田(2011)モデルと一致する。また,提案モデルでは,過去の各購買のアイデアル・ポイントへの影響度を測る記憶パラメター(ρ)はセグメント・次元毎に異なるが,一部のセグメントでは等しいとした制約を課したモデルも推定した。これは,次元毎に異なるρの推定値が似通っている場合にモデルをより頑健なものにするためである。推定されたモデルのデータへの適合度をBIC(ベイジアン情報量基準)で比較したのが表5である5)。
【95 頁】
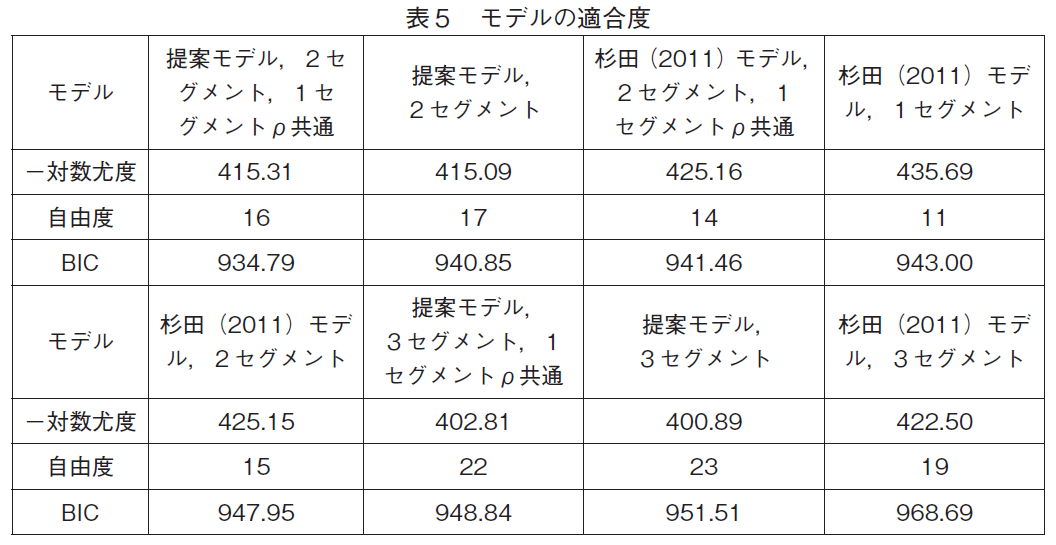
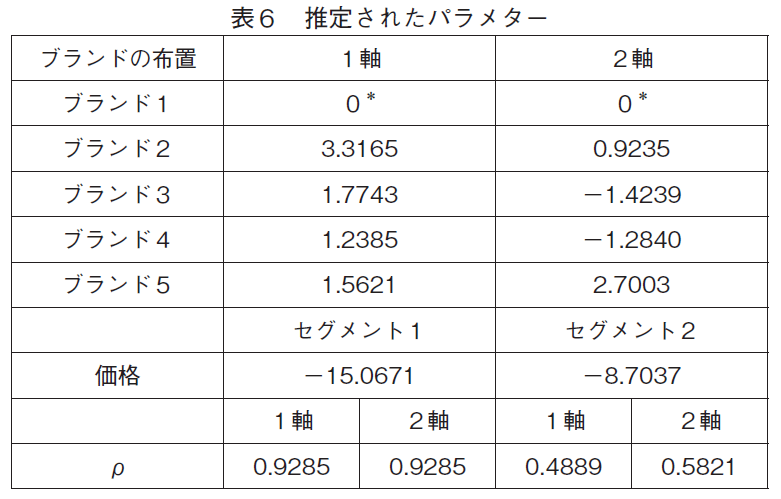
表5から適合度が最も良いのが,一つのセグメントではρが2軸とも共通である2セグメントを持つ提案モデルであり,このモデルを採用するべきことがわかる。セグメント数が少ないモデルのフィットが良いのはスキャンパネル・データに適用された潜在クラス・モデルではよく起こることである。このデータでも3セグメントを持つモデルの適合度は2セグメントを持つモデルより劣っていて,3セグメント以上のセグメント数を考える必要はなかった。この後は,採用された提案モデルの推定結果の解釈について見て行こう。採用したモデルから得られたパラメターの推定値は表6の通りである6)。
【96 頁】

表6から,このモデルのふたつのセグメントはほぼ同じ大きさ(0.5004対0.4996)であるが,軸の重要度はかなり違うことが分かる。特に,第2セグメントでは,第1軸の重要度は第1セグメントとあまり変わらないが,第2軸の重要度はその四分の一ほどしかない。つまり,セグメント2では2軸が重要ではないので,2軸でのブランドの布置と理想点の差は大きなペナルティーとはならない。相対的に,1軸上の差は大きなペナルティーとなり,この軸で理想点から離れたブランドは不利である。
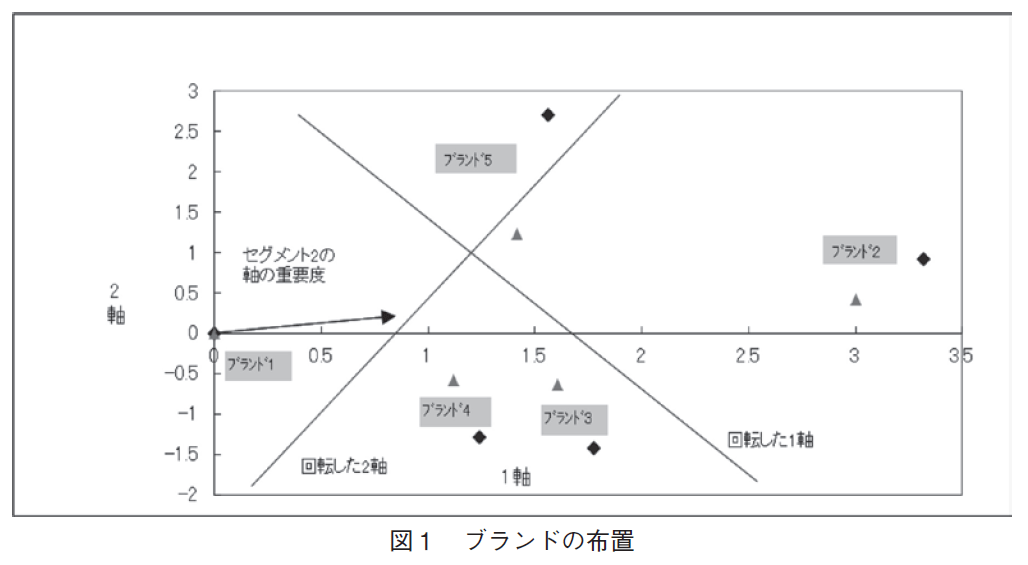
図1は推定の結果から得られた知覚マップである。このマップでは,ブランドの布置は◆で表した。また,セグメント2にとっての軸の重要度もベクトルとして書き入れてある。さらに,▲の点は,セグメント2について各軸の重要度(の平方根)とブランドの布置の積を求めて,マップ上に書き加えたものであり,重要度を加味したセグメント2にとっての各ブランドの布置になっている。マップから分かるように,重要度を加味したセグメント2のブランドの布置は,セグメント1のブランドの布置と比べて1軸ではあまり変化しないが,重要度が低いことを反映して,2軸方向で大きく動いており特にブランド3,4,5の布置が大きく近づいている。
それでは,二つの軸はどのような意味を持っているのだろうか。マップ上の「回転した軸」とラベルのある軸は,軸の解釈を助けるために,元の軸を直交回転させたものである。回転した1軸はブランドの価格戦略の差をあらわすと考えられる7)。ブランド5と1は定価と安売り
【97
頁】
の差(価格差)が激しいブランド,所謂ハイロー・プライシングを用いるブランドであり,これが1軸の左側に位置している。逆に,ブランド2,3,4は価格が安定したブランドで,これらは軸の右側にある。消費者には,価格戦略に関して好みがあると考えられる。一部の消費者は価格が安定していることを好み,他の消費者はチェリー・ピッキングができるハイロー・プライシングを好むと考えられるからである。また,回転した2軸は製法の差(による味の好み)を表す。また,軸の直交回転はブランド間の距離に影響しないので当然だが,回転後のマップでも,セグメント2では,回転前と同様にブランド3,4,5が大きく近づきブランド1と2は離れた位置にあることがわかる。
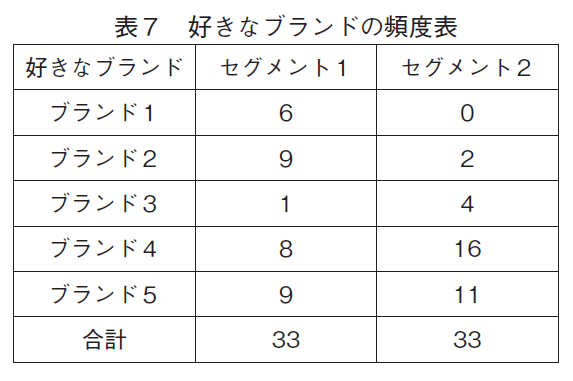
表7は,セグメント1と2それぞれに属すると判定された家計について,ブランドの布置と家計の理想点との距離から,それぞれの家計の理想点に最も近いブランドをその家計が好きなブランドとして,ブランド毎にそのブランドが好きな家計の頻度を表にしたものである。各家計は,セグメントへの所属確率が最大(2セグメントなので,確率が0.5以上)のセグメントに所属すると仮定して分布を計算した8)。セグメント1では,それぞれのブランド(ブランド3と4を同一ブランドと見ると)が一定の支持を集めているが,セグメント2では,家計の選好はブランド3,4,5に偏っている。
図2と図3は,それぞれのセグメントの知覚マップにそのセグメントに所属すると判断された家計の理想点を書き入れたものである。ブランドの布置は▲で,理想点は◆で表している。重要度の違いを反映して,図3(セグメント2)は図2(セグメント1)と横軸のスケールはまり変わらないのに,縦軸のスケールがかなり小さくなっている。このモデルでは,消費者の理想点は購買したブランドの布置の加重平均なので,ブランドの布置を結ぶ直線上に理想点が多くあれば,その2ブランド間での競争が激しいことが分かる。セグメント1では,ブランド5と2,ブランド1と3,4を結ぶ直線の近くに理想点が多いので,これらのブランド間で競争が激しく,逆に,ブランド2と3,4の間に理想点が少なく,ブランド1と5の間も同様に理想点は少ないので,これらのブランド間では競争が激しくないことが分かる。マップの中
【98 頁】
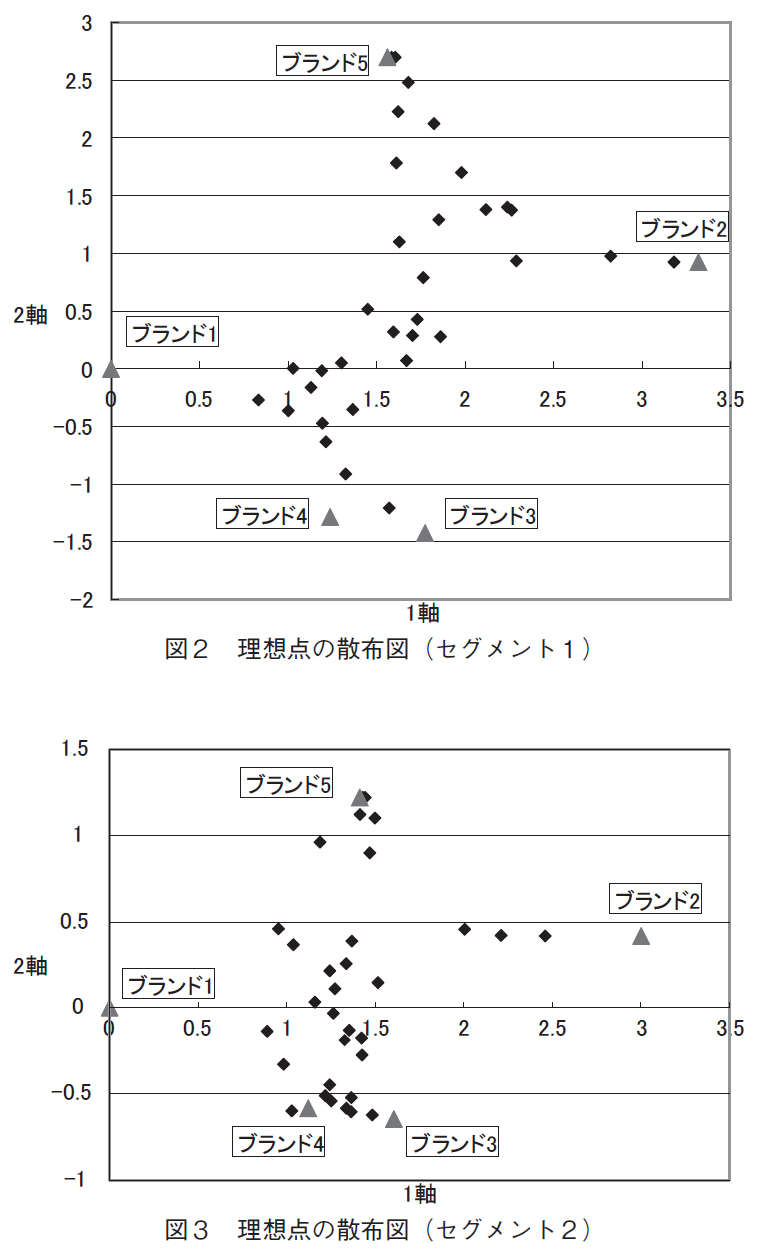
央部にある理想点はどのブランドからも購買する可能性があるが,厳密に距離を計算すれば,ブランド1と2よりもブランド3,4,5から購買する可能性が高い。
セグメント2では,縦軸のスケールが小さくなっただけでなく,ブランド3,4,5を結ぶ直線の近くに多くの理想点があり,これらのブランド間で競争が激しいのが理解できる。また,セグメント1に比べ,ブランド5と2,ブランド1と3,4を結ぶ直線の近くに理想点が格段
【99
頁】
に少なくなり,ブランド1と2は苦戦を強いられていることが分かる。セグメント1では,価格戦略が異なり,製法が同じブランド1,3,4そしてブランド2,5の間で競争が激しく,セグメント1と異なり,セグメント2では製法による好みの重要度が下がり,メーカー2の3ブランドが多くの市場シェアを占め,これらのブランド間で競争が行われ,メーカー1のブランドは置いていかれているようである。
このことは,このセグメント2の家計が,製法はもとより価格戦略という軸を基にブランドを評価しているというよりも,ブランド3,4,5を発売しているメーカー2に対するロイヤルティーが高いことを示しているのかも知れない。もうひとつ興味深いのが,ブランド1と2は遠くに離れていて,メーカー1に対するロイヤルティーは存在していないことである。つまり,セグメント1では,同じ製法で違った価格戦略を取るブランド間で競争が激しいが,セグメント2では,メーカー2のブランドに人気が集まり,このメーカーのブランド間での競争が激しいのに対し,メーカー1のブランドは置いて行かれている。
また,セグメント2ではどちらの軸(特に1軸)も重要度が低く,消費者の効用に対するこれらの軸の貢献度(ペナルティー)が低いことを示している。しかし,表6からはセグメント1の価格パラメターがセグメント2の価格パラメターよりはるかに大きいことがわかる。つまり,セグメント1は,ジョイント・スペースの影響も価格の影響も大きく,セグメント2はどちらも小さいということである。軸からのペナルティーも考慮に入れたとして,どちらのセグメントがより価格に敏感なのであろうか。平均価格における価格弾力性をセグメントごとに計算してみると,セグメント1はすべてのブランドの平均が−1.784で,セグメント2は平均−1.342となる。どちらのセグメントも価格に敏感ではあるが,セグメント1がより敏感である。
ρの値もセグメント間で異なっている。第1セグメントのρは両方の軸とも0.9285である。このセグメントでは,ρの値が高いので,理想点は多くの過去の購買に依存し,移動量は少ない。したがって,このセグメントの家計は価格に敏感に反応するが,そのことによって理想点は簡単には移動しないということである。これがマップの中央部に家計の理想点が多い原因であろう。これに対して,第2セグメントではρの値が第1軸は0.4889,第2軸も0.5821と低いので,理想点が移動しやすい。したがって,セグメント2の家計が価格に反応すれば,そのことによって,理想点は,セグメント1に比べて大きく購買したブランドに傾くことになる。
4 結果の要約
本論文では,スキャンパネル・データからジョイント・スペース・マップを選好の内的分析によってつくるブランド選択モデルの中で,軸の重要度とマーケティング変数への反応が異なる消費者セグメントと家計毎にダイナミックに変化するアイデアル・ポイントを持った新しいブランド選択モデルを提案しデータに適用した。提案モデルのフィットは軸の重要度の異質性を考慮しないモデルより良好であった。
データ分析の結果から,家計はほぼサイズが等しい二つのセグメントに分かれ,セグメント1は同じ製法をとるブランド間での競争が激しく,価格に敏感ではあるが,購買したブランドへのロイヤルティーは低いことがわかった。セグメント2はメーカー2へ人気が集中し,価格への敏感さはセグメント1ほどではなく,購買したブランドに対するロイヤルティーが高いことが示された。このデータ分析から,アイデアル・ポイント・モデルに軸の重要度を入れるこ
【100
頁】
とは有益で,セグメントごとにブランドの評価法が異なることが示唆されたことは興味深い。ただ,今回の結果はひとつの製品カテゴリーの結果に過ぎず今後多くのカテゴリーで検証を続ける必要がある。
参考文献
1.Allenby, G. M. and P. E. Rossi (1999), “Marketing Models of Consumer Heterogeneity,”Journal of Econometrics, 89, 57-78.
2.Andrews, R. L.., A. Ainslie and I. Currim(2002), “An Empirical Comparison of Logit Choice Models with Discrete Versus Continuous Representation of Heterogeneity,” Journal of Marketing Research, 39, 4, 479-487.
3.Elrod, T.(1989), “Choice Map: Inferring a Product-Market Map from Panel Data,” Marketing Science, 7, 1, 21-40.
4.Elrod, T. (1989), “Internal Analysis of Market Structure: Recent Developments and Future Prospects,” Marketing Letters, 2, 3, 253-266.
5.Erdem, T. (1996), “A Dynamic Analysis of Market Structure Based on Panel Data,” Marketing Science, 15, 4, 359-378.
6.Guadagni, P. M. and J. D. C. Little (1983), “A Logit Model of Brand Choice Calibrated on Scanner Data,” Marketing Science, 5, 2, 203-238.
7.Inman, J. J., J. Park and A. Sinha (2008), “A Dynamic Choice Map Approach to Modeling Attribute-Level Varied Behavior among Stockkeeping Units,” Jounal of Marketing Research, 45, 1, 94-103.
8.Lee, J. K. H.,K. Sudhir and J. H. Steckel (2002),” A Multiple Ideal Point Model: Capturing Multiple Preference Effects from within An Ideal Point Framework,” Journal of Marketing Research, 39, 1, 73-86.
9.片平秀貴(1990),「マッピングを伴う市場反応モデル」,『マーケティング・サイエンス』,36,13-27頁。
10.里村卓也(2004),「マッピングを利用した市場反応の動的分析」,『マーケティング・サイエンス』,Vol.12,No.1・2,1-23頁。
11.杉田善弘(1998),「文脈効果とジョイント・スペースを組み込んだブランド選択モデル」,『消費者行動研究』,Vol.5,No.2,13-26頁。
12.杉田善弘(2011),「消費者セグメントと次元毎に変化するアイデアル・ポイントを持つブランド選択モデルによるジョイント・スペース分析」,『経済論集』 (学習院大学経済学会),Vol.47,No.4,355-371頁。
13.高根芳雄(1980),『多次元尺度法』 (東京大学出版会)。
14.土田尚弘(2009),「オケージョン効果を考慮した清涼飲料水カテゴリーのジョイント・スペース・マップ」,『経営と制度』 (首都大学東京),Vol.7,1-15頁。
15.長谷川翔平(2011),「動的ジョイント・スペース・マップ」,日本マーケティング・サイエンス学会第89回研究大会研究報告。