【141頁】
世界自動車製造業2014年度株価成長の時系列分析
学習院大学 経済学部 白田由香利
日本経済研究センター 佐倉 環
岩手県立大学 バサビ・チャクラボルティ
要約
世界自動車製造企業175社の2014年度の株価成長について時系列分析する。株価上昇率の高い企業を発見するため,我々は従来の時系列データクラスタリング手法ではなく,上昇率の違いを抽出可能なAmplitude-basedクラスタリング手法を用いた。これにより,2014年度の1年間では,インドの自動車製造業において株価上昇が顕著であることを発見した。次に,企業の規模を含めて2013年度から2014年度への業界全体の変動と会社固有の局所的な変動を解析するため,収益額PLBT及び,売上高を用いて統計的形状分析shape analysisの手法による分析を行った。2013年度から2014年度の変動においては,PLBTよりも売上高の変化率が大きく,業界全体として成長をしており,上位と下位の企業の差は縮まる傾向にあることが分かった。また,株価上昇率が高いインドの企業は,全体のフォーメーションの中での位置は2014年度においては業界平均よりも下位に属し,MULTI SUZUKI INDIAを除いては相対的に見て成長率は平均に届いていないことが分かった。2014年度の動きの特徴として,インド自動車製造企業は規模は小さいが,株価上昇率で顕著な成長変動を示したことが抽出できた。
1. はじめに
本稿では,世界自動車製造企業175社の2014年度の株価成長について時系列分析する。2020年3月に起こったCOVID-19の影響で世界中の自動車製造業は甚大な損害を被った。世界の多くの自動車製造業の株価が2020年3月下旬に史上最悪の下落を記録した。しかし多くの企業はその底値から急激に回復を開始した。その中で,日本自動車製造業の株価回復率は高いとは言えなかった[1, 2]。現在,自動車製造業界では,電気自動車(EV)へのパラダイムシフトが急速に進行中である[3]。その急変革の中で日本のEVへのパラダイムシフトはやや遅れているように感じる。我々の研究目的は,10年の長い期間において自動車製造業界のパラダイムシフトがどのように起こってきたかを時系列データ分析として解析することである。自動車業界では,系列の瓦解が進むと言われているが,実際にこの10年間にどのような変化があったのかを,株価の時系列変化分析を使って解析していきたい。手始めとして,本稿では2014年度を取り上げ,株価分析及び,収益及び売上高の変化を分析する。これが第1番目の研究目的である。
第2節では,10年スパンの中での2014年の状況を概括する。第3節では,2014年度の株価成 【142頁】 長率の高かった企業をクラスタリングにより抽出する。クラスタリング手法としてAmplitude-based clustering法を用いる[4]。4節では,収益及び売上高成長率の2014年度と前年度の変化を統計的形状分析(Statistical Shape Analysis)の手法[5]を用いて分析する。最終節はまとめである。本稿で2つの新しい手法を用いるが,論文の目的の2番目は,経営分析においてこうした手法の適応例を示すことである。Amplitude-basedクラスタリングは機械学習の時系列データクラスタリングのアルゴリズムで我々が新たに開発した。Shaple analysis手法は生物学の分野で発展してきた手法であるが,これを経済経営の分析にいち早く用いたのは我々である。こうした新手法の特長を実際の例により示していく。
2.2014年度の概要
2012年から2021年の10年スパンでの変動のうち,2014年度の変動の概要について述べる。本稿で使ったデータは,ビューロー・ヴァン・ダイク社の企業データベースOrbisから検索した。
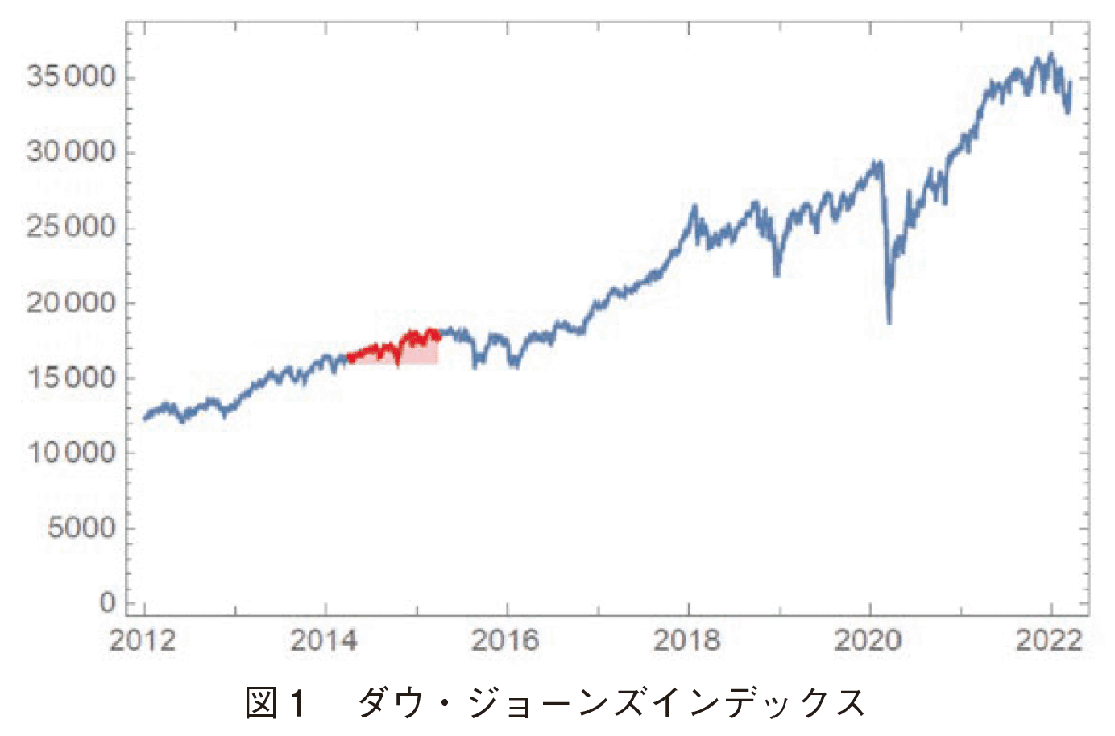
まず市場の動きであるが,2014年度は10年のスパンの中で見ると,比較的順調に株価が成長した時期と言える。図1にダウ・ジョーンズインデックスの変化を示した。図1はWolfram社のMathematicaのデータベース機能を用いて検索し,Mathematicaで描いた。赤のマーク部分が2014年4月から1年の変化である。後に起こる2018年のブラック・クリスマスの株価暴落(2018年12月24日),COVID-19による2020年3月後半の株価暴落に比較すると,大きな暴落も無く比較的穏やかに株価が増加している様子が見られる。
次に代表的な自動車製造企業8社について,その税引前利益/損失(PLBT:Profit/Loss before Tax)の動きを図2に示した。比較のため,単位は1000USドルに換算してある。全て年次データであるが,世界の企業間には会計年度期間の違いがある。Orbisで本データを取得した時期が2021年3月中旬のため,日本企業の多くは最終年度が2019年度であり,アメリカ企業の多くは最終年度が2020年度となっている。データを読む際,こうした会計年度の違いがあることに注意して頂きたい。図2より,PLBTに関してはVWとTOYOTAがトップを取ってき
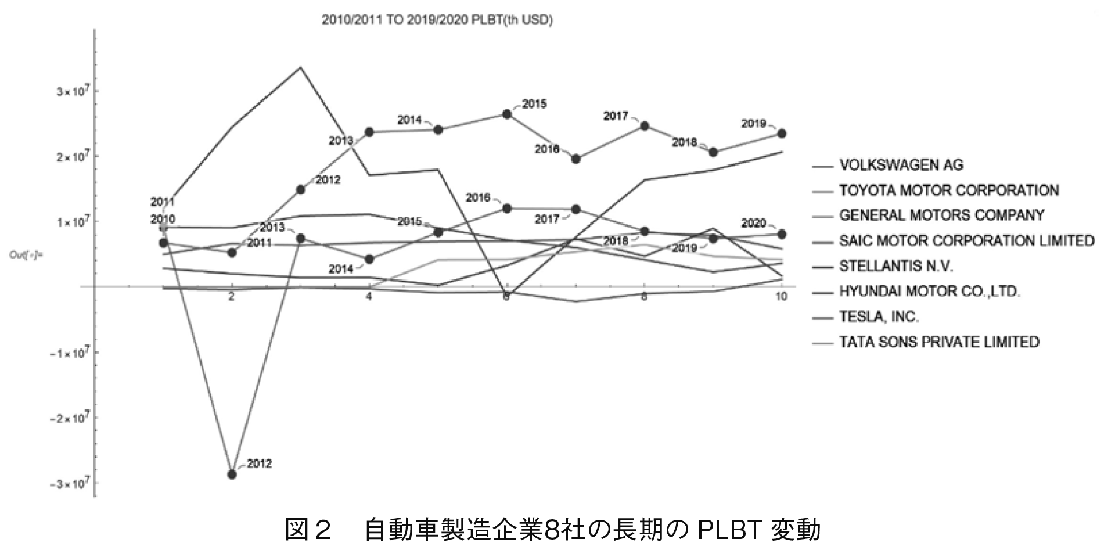
【143頁】 たことが分かる。2013年度トップとなった。TOYOTAは,それ以降7年連続で1位を維持している。2020年以降急激な成長を見せるTESLAは,この期間はまだ収益が黒字と赤字の間で動いている。中国のSAIC(上海汽車集団)は,第一汽車,東風汽車と合わせて中国の三大自動車製造企業であるが,この10年PLBTに大幅な変化は見られない。
2014年度という年は,TOYOTAがPLBTを急成長させた2年目にあたり,そこから安定的TOPとなる。VWは2014年度にPLBTが2位に転落したが,その後さらにPLBTが赤字になるほどの底値になるものの,以降は再び急上昇期に入る。GMに関しては,2014年度は赤字転落から急上昇して2年目になった年である。
3.株価変動のAmplitude-basedクラスタリング
本節では,2014年度4月から1年間の株価変動を時系列データクラスタリング手法で分析する。目的は2014年度に株価を急上昇させた急成長企業を抽出することである。始めにデータと分析手法を説明し,次にクラスタリング結果を述べる。
3.1 株価データ
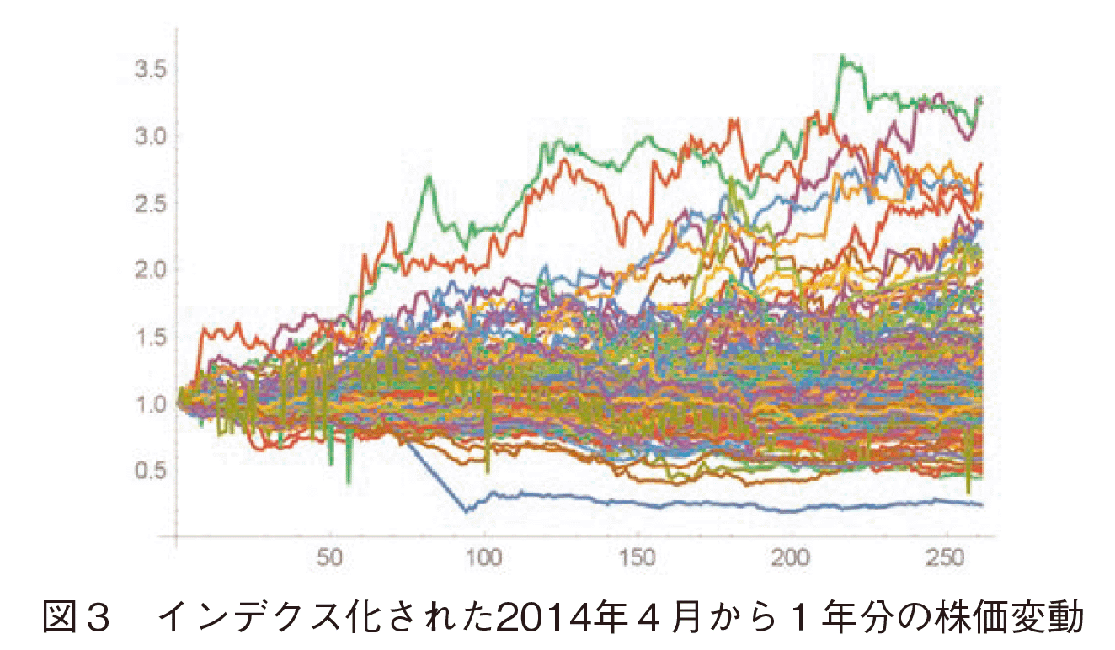
株価データは前述した企業データベースOrbisを使った。世界の株式市場の営業日は異なるので,日曜土曜を除き,当該1年で欠損値が30個以下の企業に絞った。その結果残った企業数は175社である。欠損している株価は線形補完で補った。その株価データを2014/4/1の値を1として,インデックス化した(図3参照)。データ中には,変動が著しく大きく修正の可能性が考えられる企業が2社(ロシアの企業)あったが,分析結果の解釈には問題がないのでデータは残したままクラスタリングを行った。
【144頁】
3.2 Amplitude-basedクラスタリング手法
時系列データクラスタリングは,株価のように変動するデータのパターンの類似性を計測し,類似度を距離として出力する機械学習の手法である。距離が近い企業とは,株価変動パターンが類似していることを示す。そのため,ポートフォリオ作成のために,広く使われている。代表的なアルゴリズムとして,k-Shapeクラスタリング[6, 7],Dynamic Time Warp(DTW)距離[8, 9]によるk-mean法がある。k-Shape及びDTWによる株価分析の研究は多数発表されている。現在,この2手法は最も広く使われている手法であるが,我々のETF及び株価による実験結果では,人間が望むような分類をしてくれるという意味ではk-Shape法のほうが若干優れていた[10, 11]。
しかし,本稿で扱うインデクス化されたデータ変動の比較には,k-Shape法は使えない。理由はk-Shape法は入力データの標準化を行う必要があるからである。つまり,標準化により平均を0,分散を1とすると,株価成長率の強さの情報は失われてしまい,例えば,殆ど上下変動のないフラットな変動であっても,その微小な変動が拡大されるからである。
我々の目標は,上昇率の強さの情報を残したままクラスタリングすることである(図3参照)。こうしたインデクス化したデータによる比較は経済経営の分野で多く行われるが,伸びの強さまで含めた比較はk-Shapeでは行えない。DTWによる手法においても,入力データは標準化してから行われることが多く,データ標準化を想定している。階層化クラスタリング手法では,ポートフォリオ作成のためプラドのHRP(Hierarchical Risk Parity)法[12-14]が広く使われているが,HRP法の距離定義では伸びの強さの情報が欠落してしまうため,適さない。理由はHRP法の距離の定義においては,ピアソンの相関係数が使われているためである。ピアソンの相関係数では共分散を標準偏差で割り算しているので,結局標準化したことと同様の結果となり,この強さの情報は削除されてしまう。
我々はインデクス化された変動パターンの上昇率比較を行いたい。この問題を解決するために,白田とバサビはAmplitude-based clustering法を開発した[4]。Amplitude-based clustering法では,2つのデータ間のユークリッド距離を計算し,次に,全体のn個のデータとのユークリッド距離の間で再度ユークリッド距離を計算し,それを距離として用いる。この距離の定義の中でデータ標準化は行っていない。これにより,amplitude情報を残したまクラスタリングが行える。
【145頁】
3.3 クラスタリング結果
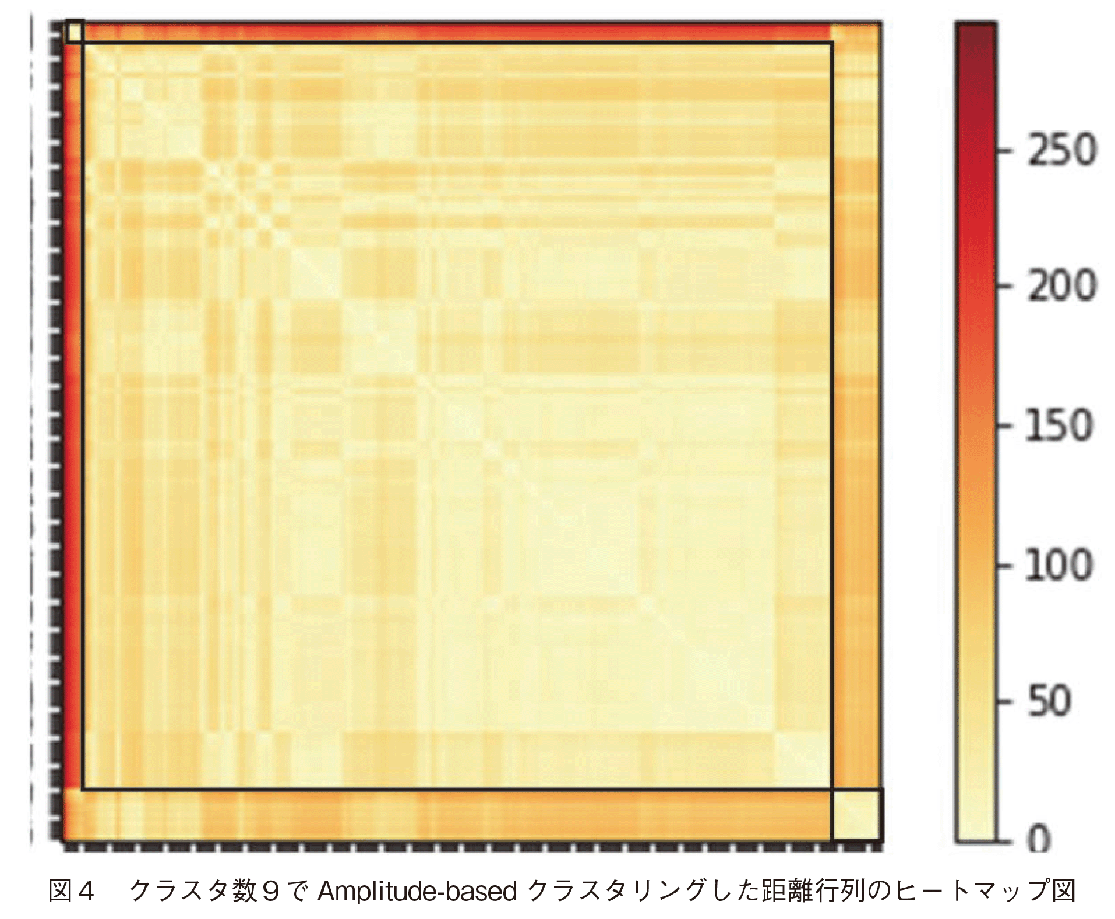
本節では,世界自動車製造企業の株価インデクスをAmplitude-based clusteringでクラスタリングした結果を示す。結果として得られた距離行列のヒートマップ,及びデンドログラムを図4と図5に示した。クラスタ数kは9とした。Amplitude-basedクラスタリングでは,ユークリッド距離をまたユークリッド距離計算した指標を距離としているので,この距離行列は正確には,「距離の距離を示した行列」である。
図4は対角線上にこの距離が近いものが並ぶように企業名を並び替えた結果である。この操作を准対角化と呼ぶ[13]。デンドログラムの企業名の並びも准対角化した後の企業リスト順になっている。図4のヒートマップ図では,中央に多数の企業からなる最大のクラスタが見られる。ここに属す企業の変動は平均的なもので,株価急上昇の企業のクラスタは殆どが左上と右下に位置する。
【146頁】
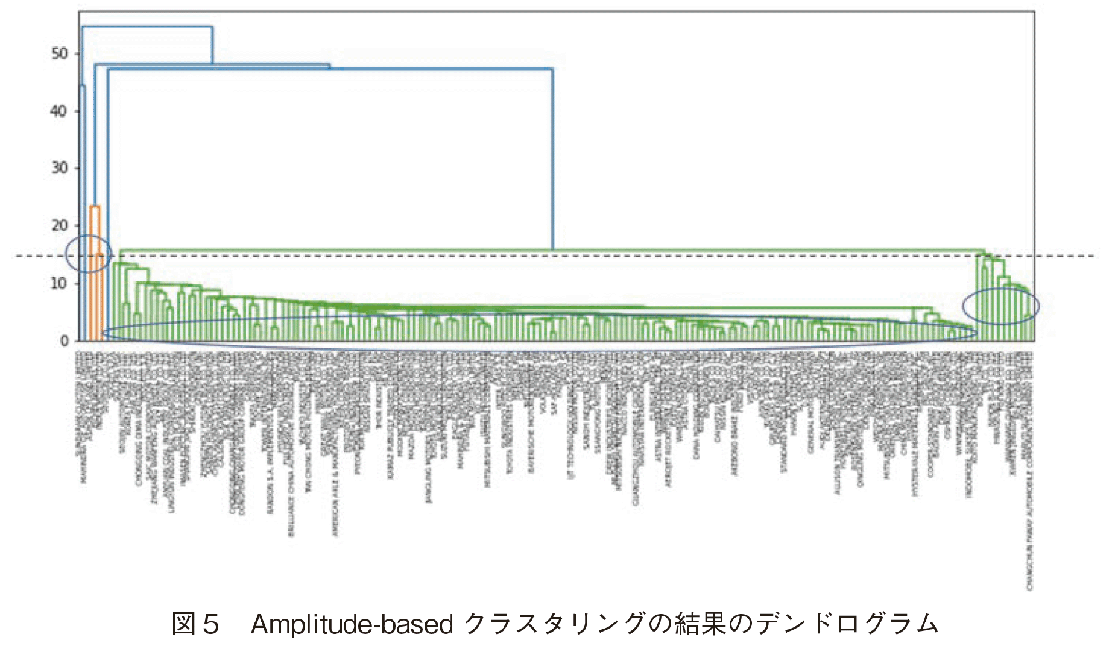
クラスタリング結果を示すデンドログラムでは,縦軸が2クラスター間の距離を表わす。図5のデンドログラムではクラスター数kを9と指定した。k=9にした結果とは,図5において水平方向の点線を垂直に移動して,9個の接点をもっている位置になるようにする。この接点より下に位置する企業が同じクラスターに所属する企業となる。左端から6企業は,1企業が1クラスターを形成している。その右隣に最大クラスターCluster#6が並ぶ。右端に2番目に大きいCluster#7が並ぶ。デンドログラムに表示された第1,第2の最大クラスターは,図4のヒートマップでは,中央と右下の四角として表示されている企業群に対応する。
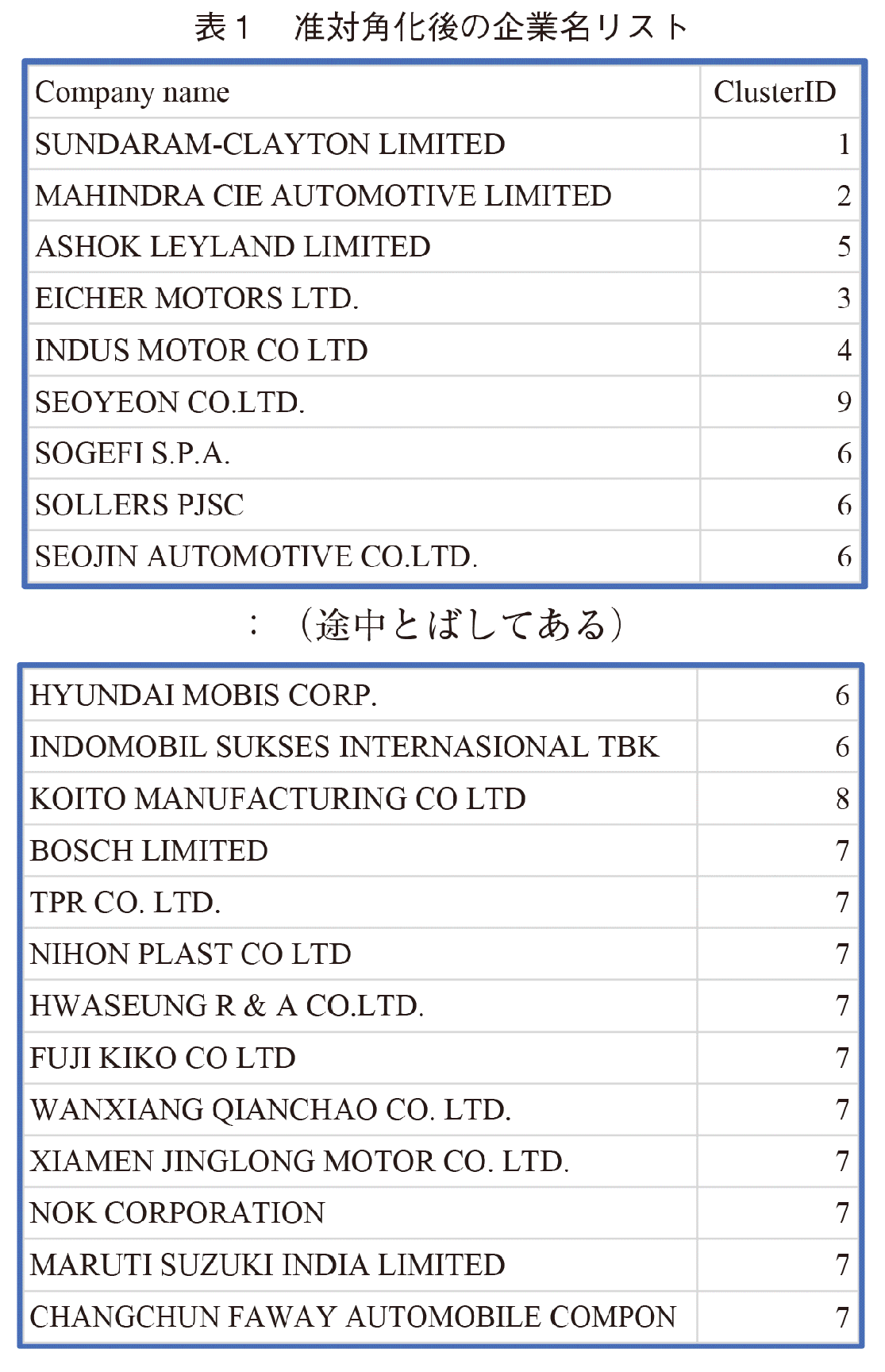
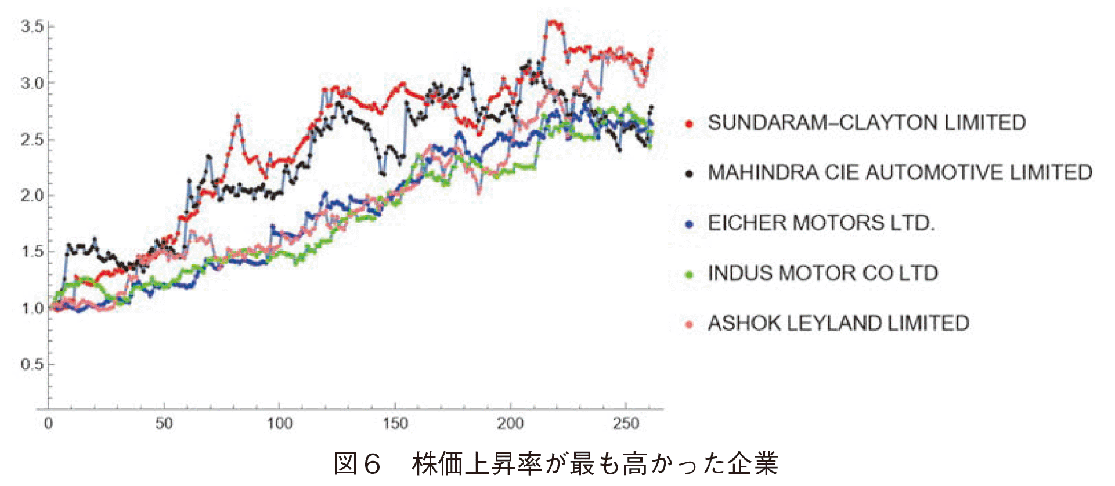
准対角化後の企業名の並びに従い,先頭と末尾のクラスタIDと国名を表1に示した。Cluster#1,#2,#5,#3,#4は1企業で1クラスターを形成するほど他の企業とは変動パターンが異なる(図6参照)株価上昇率が非常に高い企業である。図6の横軸は営業日数,縦軸は株価情報率である。図6に示すこれらの企業は殆どインドの企業である。INDUS MORTORはトヨタ自動車とパキスタン,ハビブ財閥との合弁生産販売会社である。INDUS MOTORのみがパキスタンの企業であるが,地理的にみてパキスタンはインドの西に隣接するので,2014年にインドの自動車製造業が躍進したことが分かる。日本のSUZUKIがインドに進出したSUZUKIの子会社MULTI SUZUKI INDIA[15, 16]は,後述するCluster#7に名前が入っているが,急激に株価を上昇させている。Cluster#9のSEOYEONは,2014年度途中から株価急落を示している。
【147頁】
【148頁】
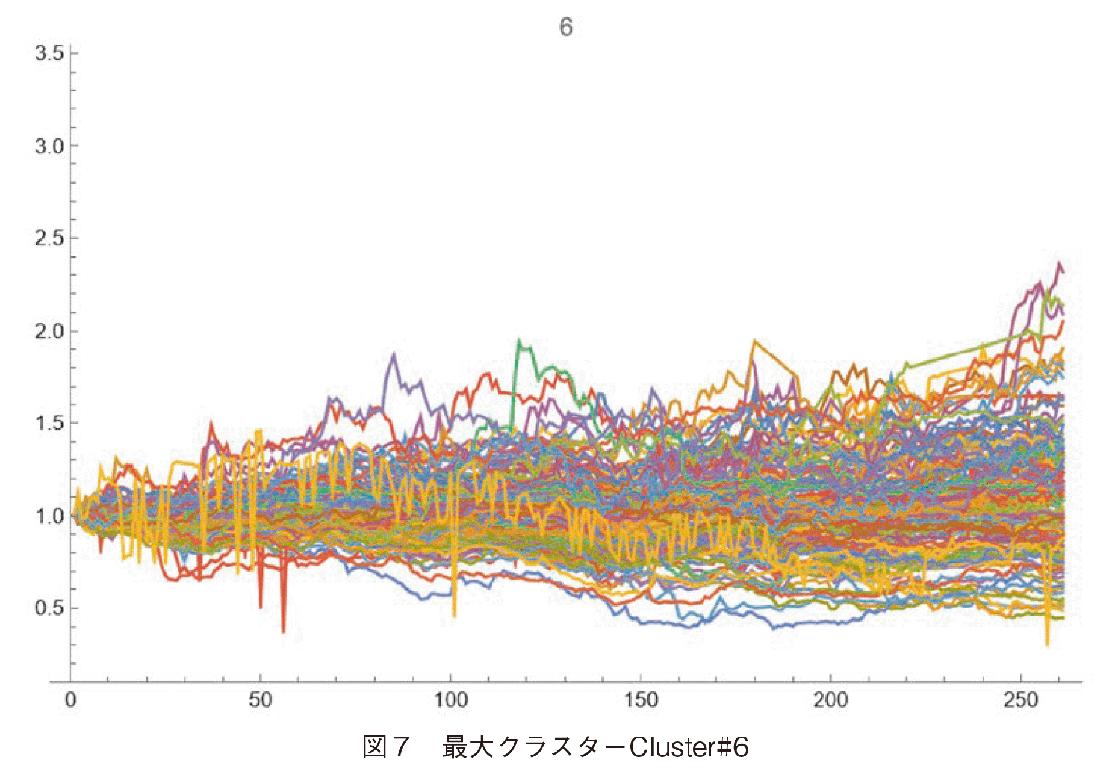
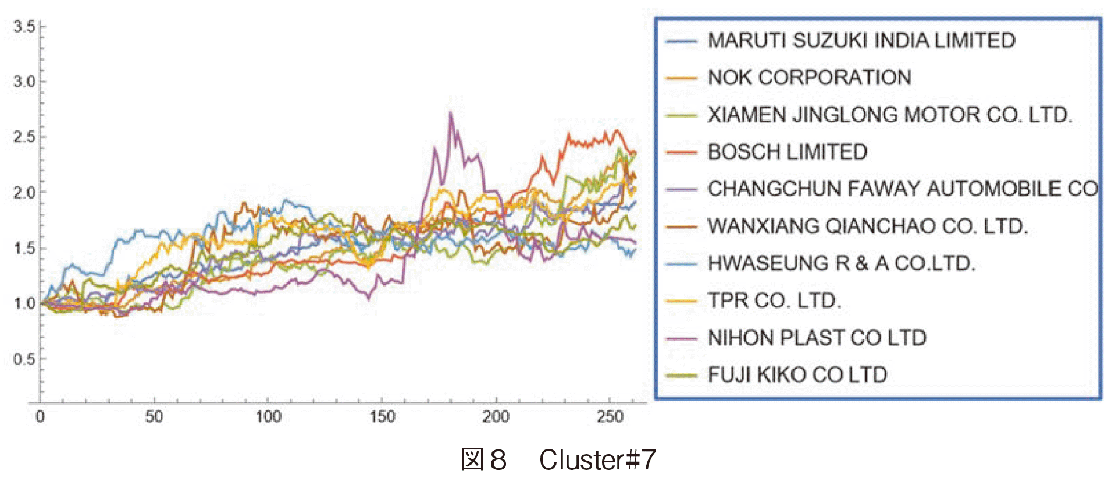
図7に最大クラスターであるCluster#6の株価変動の様子を示した。図中には前述した通り変動が不可解なロシアの企業2社が含まれる。このクラスターは,成長率も下落率もそれほど顕著ではない平均的な変動を示した企業群から構成される。それに比較して図8のCluster#7は,前述したインドの急成長企業に準じて株価を大幅に上昇させた企業のクラスターであり,会社名と国名は表2に示した。
【149頁】
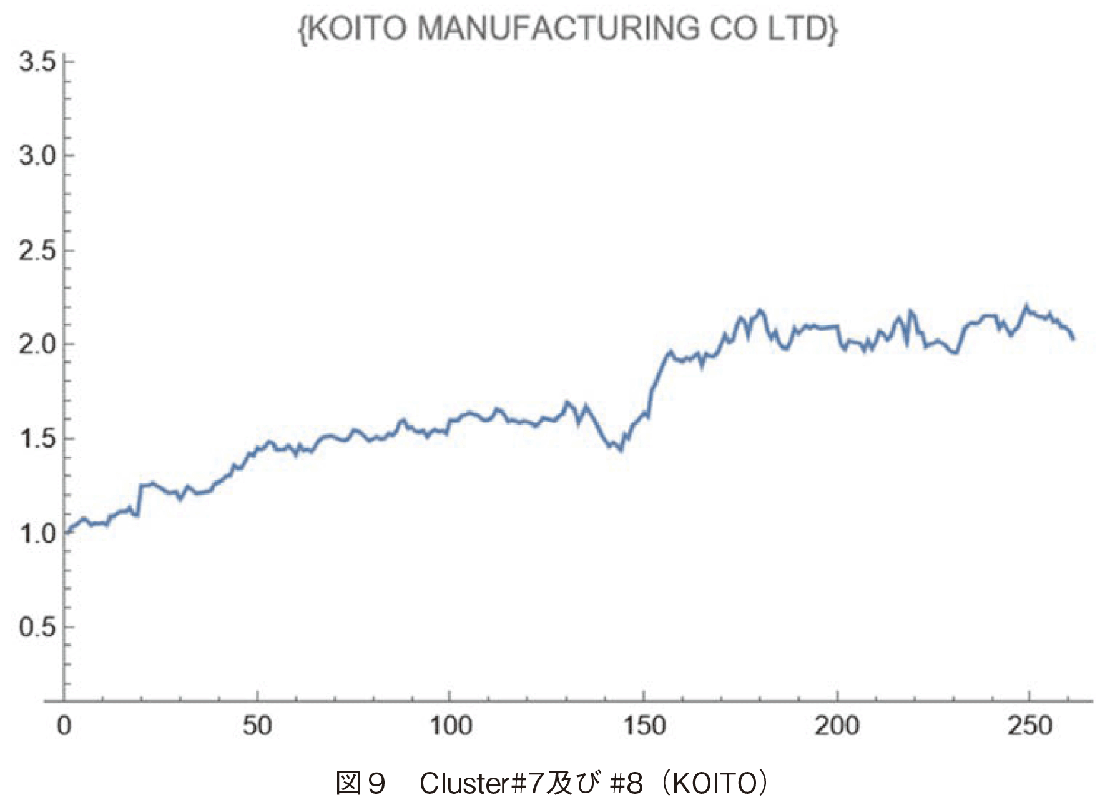
Cluster#7とCluster#8のKOITOは距離が近い。これは図5のデンドログラムを見れば分かるが,Cluster#7の左隣を見ると,KOITO, BOSCHの順で名前が並んでおり,もしk=8にした場合は,KOITOはCluster#7のメンバーとなる。このBOSCHはインドのBOSCHであり,ドイツ本国のBOSCHではない。MARUTI SUZUKI INDIAはこのCluster#7に所属する,図8より2014年にも順調に株価を上昇させたことが分かる。
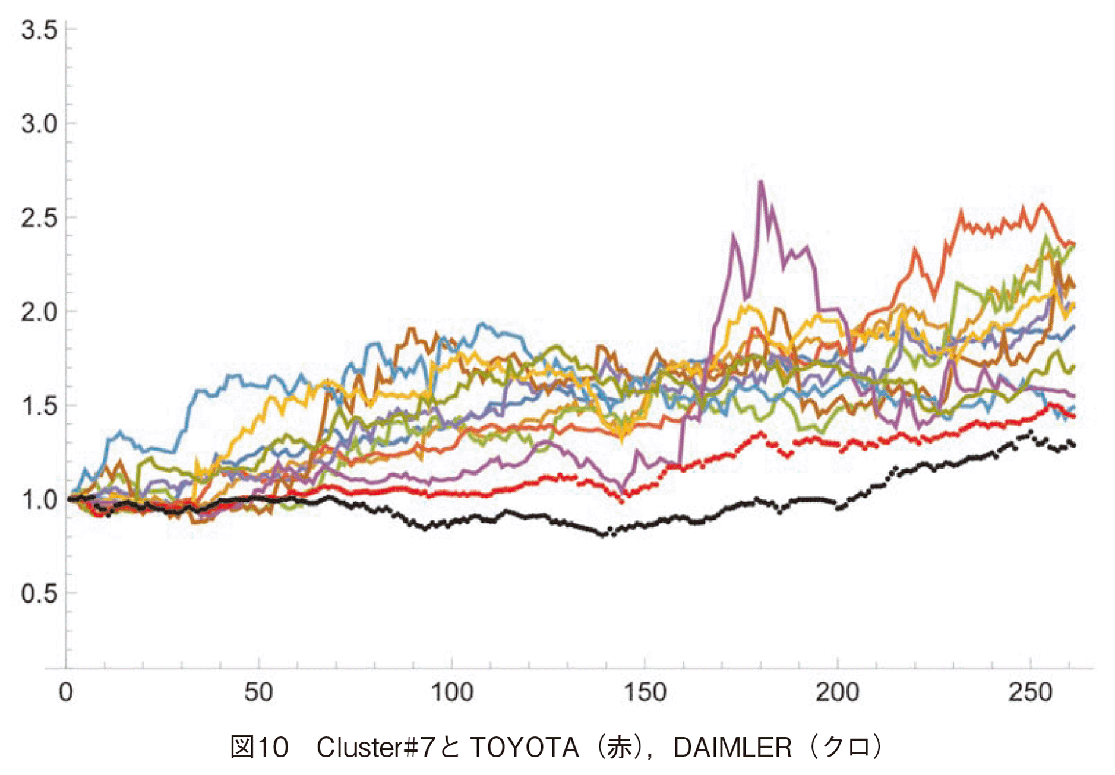
Cluster#7を国別にみると,日本,インド,中国,韓国の企業から構成されている。年度末の株価倍率だけを見るとCluster#6にも2倍を超える企業が存在するが,Amplitude-basedクラスタリングはパターンの類似性を比較しており,単に最終倍率を見ているのではない。Cluster#7の企業が順調に株価上昇を果たしたことを示すため,Cluster#6に属するTOYOTA及びDAIMLERの変動をCluster#7と比較した(図10参照)。TOYOTA, DAIMLERの株価上昇パターンに比較して,Cluster#7の企業の株価上昇が大きいことが分かる。
【150頁】

あえて2014年度の最終的な株価上昇インデックスだけを見ると,1.7倍以上となる企業が24社あり,うちインド6社。中国12社であった。例えば,SAICは約1.8倍であるが,パターンはCluster#6に属している。
【151頁】
3.4 まとめ
2014年度の自動車製造業の株価パターンを時系列インデクス化しAmplitude-basedクラスタリングした結果,インドなどの自動車製造企業5社が大きく株価を上昇させたことが分かった。そのうち1社はパキスタンのINDUS MORTORであった。その倍率は1年で2倍から3倍になる。これらの企業は急成長しているので変動パターンが独立しており,各社が1個のクラスターを形成していた。ついで,急成長した企業群はCluster#7及び#8として抽出できた。その中には,MURTI SUZUKI INDIA及びBOSCH(INDIA)のインドの2社があった。株価上昇パターンの類似性ではなく,単純に最終的な株価上昇率を見ると,1.7倍以上となる企業の中にインド6社,中国12社が含まれていた。クラスタリングの結論としては,2014年度はインド及び中国企業の株価が急上昇したことが分かった。
4.統計的形状モデルによる時系列変化の分析
本節では,統計的形状分析という手法を用いて,2013年度と2014年度のPLBTと売上高の時系列変化を全体のフォーメーションとして分析し,また各企業の局所的変化を数値で表現し分析する。
4.1 統計的形状分析で解決できる課題
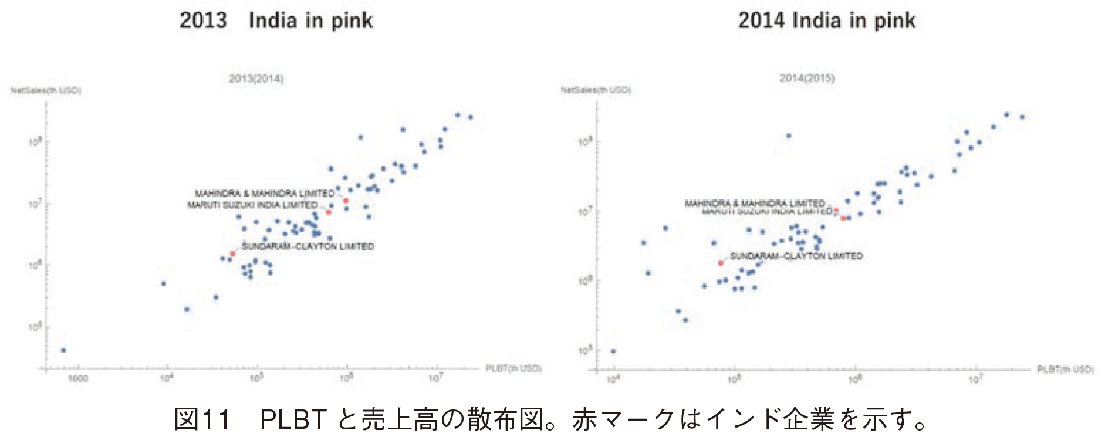
本節では,統計的形状分析をなぜ使うのか,それによってどのような問題が解決可能となるのかを説明する。例えば,147社中でインド自動車製造企業のPLBTと売上高の2013年度と2014年度の時系列変化を分析したいとする(図11参照)。企業のPLBTの成長率は計算できる。しかし,全体の中での相対的な伸び率を客観的に示す手法が過去にはなかった。それは全体が構成するフォーメーションの標準化を行う手法が発見されていなかったからである。全体のフォーメーションはどう変化していて,その変化の中で特定企業が他とは異なる特徴的変化を示すことを,標準化した後の数値として客観的に示す。統計的形状分析はこれを可能にした。
【152頁】
統計的形状モデル(statistical shape model)は,幾何学的統計学(geometry-driven statistics)とも呼ばれるが,英国Leeds大の研究グループを中心として形成された新しい分析手法である[5, 17]。元来本手法は,生物の進化の時系列データ分析のために構築された手法であるが,白田他は,この手法が人文科学一般の時系列データ分析にも利用可能であることに着目し,経済データを中心に多くの論文を発表した[18-23]。また,この手法の普及促進のため,インドネシアの研究チームと共同で,統計的形状分析の基礎を分かりやすく学べるような可視化教材も開発しWEBで公開している[24, 25](https://www-cc.gakushuin.ac.jp/~20010570/mathABC/SELECTED/ShapeAnalysis/)。この可視化教材では,貴重なジャワ原人の骨格データを利用させて頂き,統計的形状モデルが元来発明された生物学のケースで説明している。
統計的形状分析手法とは,(1)形状座標の多変量統計学,及び(2)薄板スプライン関数に基づく変形の解析の2段階から構成される。プロセス(1)では,位置移動,回転,拡大縮小といったアフィン変換で表現される全体的な変化の傾向を抽出する。プロセス(2)は,アフィン変換では表現できない非アフィン変換部分の分析であり,局所的な形状変化を分析する[17]。これは,仮想無限薄板の屈曲エネルギーを最小化するように,形状を薄板スプライン関数で表現し,薄板スプライン関数の各標識点での基底関数の線形結合によって非アフィン部分を表現する。局所的な形状変化は,屈曲エネルギー行列の固有ベクトルの線形結合で表され,その固有ベクトルが「歪み」変化の方向を示している。統計的形状分析の利点は,全体の中での各データの相対的な動きを固有ベクトルに基づいた分析結果として,主観無しの数値表現にできる点である。
本分析ではアフィン変換で表現される全体的な変化の傾向と,非アフィン変換部分により,他の標識点(本稿では各企業データ)と大きく異なる標識点を抽出する。
4.2 PLBTと売上高のデータ標準化
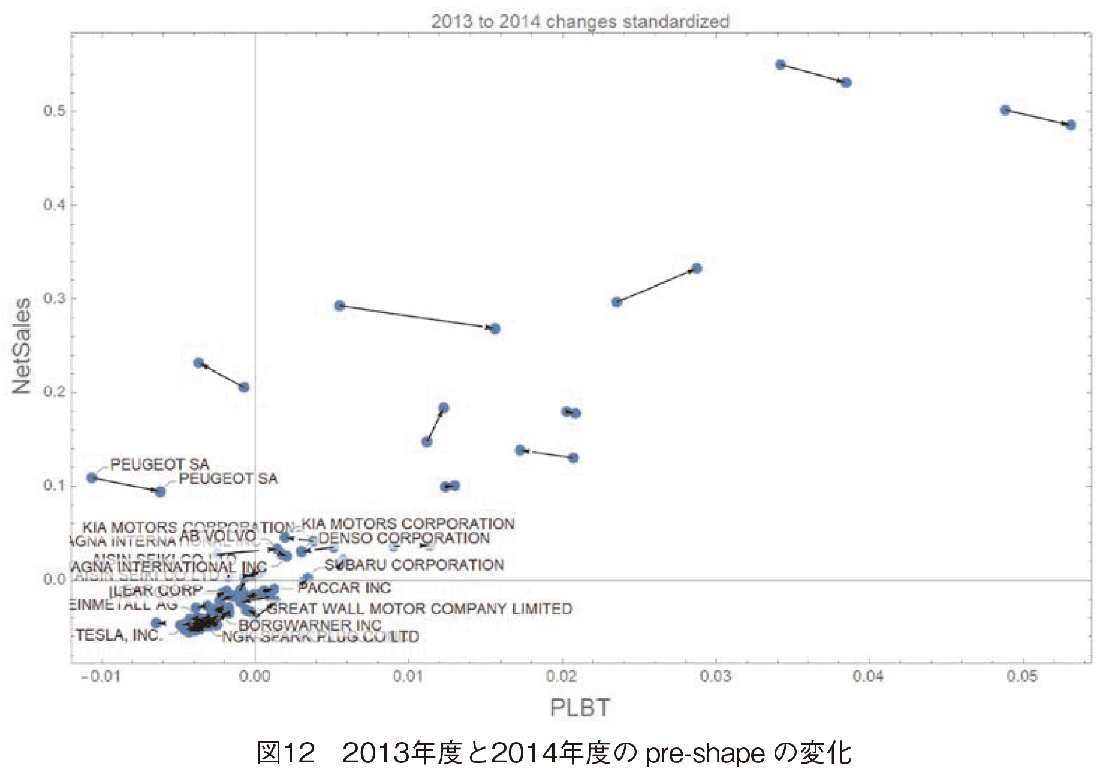
各企業を,PLBTと売上高で表現し,その2013年度と2014年度の変化を追跡する。図12の散布図では,横軸にPLBT,売上高を縦軸にした。入力データには単位がついていて,本事例では1000米ドルであるが,統計的形状分析においては,初めに入力データを標準化し,pre-shapeという形式にするため,単位は消失する。換言すると,pre-shapeに変換する加工は,データ標準化に相当すると考えてよい。
図12に2013年度と2014年度のpre-shapeの変化を示した。散布図右上の2社(VWとTOYOTA)を見ると,PLBTは他企業に比較し相対的に伸び,売上高は相対的に減少したことがこの図から分かる。軸のスケール値は,横軸の最大値が0.05,縦軸の最大値が0.6である。よって売上高の変化のほうが大きい。軸のスケールを同じにした場合,PLBTの変化の方向は殆ど無視できる程度になる。
【153頁】
前述したように,pre-shapeに変換する操作は,標準化操作である。以下にその定義を述べる。まずセントロイドサイズを以下のように定義する(Nは総データ数)。

セントロイドサイズは,各データの重心からのユークリッド距離の平方和のルートである。 まず,重心が原点になるように全データを移動した後,各データ座標をそのセントロイドサイズによってスケーリングし,pre-shapeの座標を求める。このようにしてpre-shape座標を求める。
4.3 アフィン変換と非アフィン変換の変化
次に,2013年度と2014年度のpre-shapeの変化を見ていく。その時系列変化は,アフィン変換部分と非アフィン変換部分に分けて分析する。アフィン変換部分のみの変化を図12と図13に示す。
【154頁】
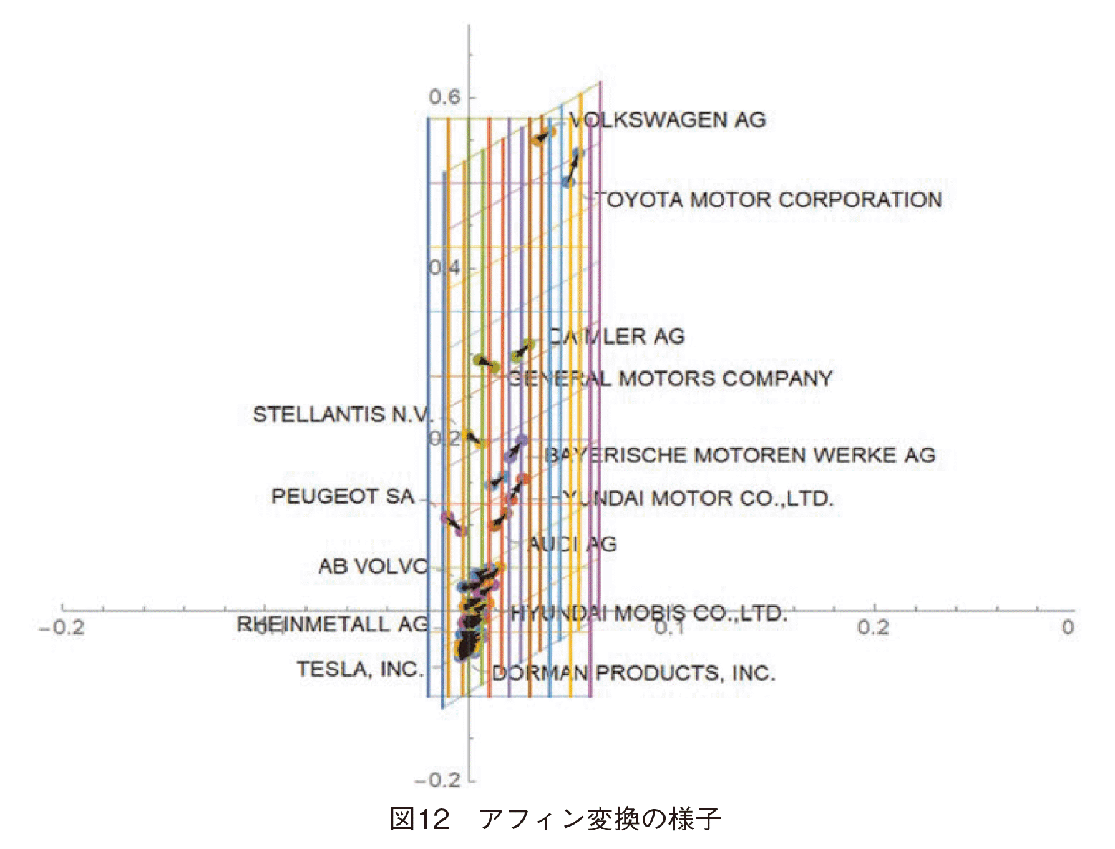
まずアフィン変換のみを図12に示した。矢印の起点が2013年度,終点が2014年度を示している。アフィン変換は全体的な傾向を示す。全ての企業のPLBTは増加傾向を示している。売上高の時系列変化は,向かって右半分の企業は売上高増加,左半分の会社は売上高減少を示していて,反時計回りに渦を巻くように変化している。次に格子に着目してみる。図12を別々に表示した(図13参照)。

【155頁】
左図が2013年度の,つまり起点のpre-shapeであり,右図が2014年度のデータにアフィン変換のみ施した後のpre-shapeである。格子はトランスフォーメーション・グリッドと呼ばれ,フォーメーションの変化の認識を容易にする。アフィン変換のグリッドの色とデータの点の位置関係を見ると,グリッドと各データの位置関係は変化していないことに注目して頂きたい。
統計的形状分析では,データが移動するのではなく,このようにトランスフォーメーション・グリッドの方が変化する。同じデータが移動したように見えるが,それは空間がどのように変化や歪みを生じたか,という視点で表現する。アフィン変換は格子に局所的な歪みは生じず全体的に力がかかり変形されたかを示す。一方,後述する非アフィン変換では,薄板スプラインの板が歪みによって変形する。これらの空間の変化の様子をトランスフォーメーション・グリッドによって可視化している。
次に非アフィン変換による変化のみを見る(図14参照)。売上高の1位TOYOTAと2位VWの企業の局所的な動きを見ると,周囲よりも(この場合,周囲に企業はないが)売上高が大きく減少していることが分かる。これは,全体的傾向では売上高上昇のエリアであるが,ローカ
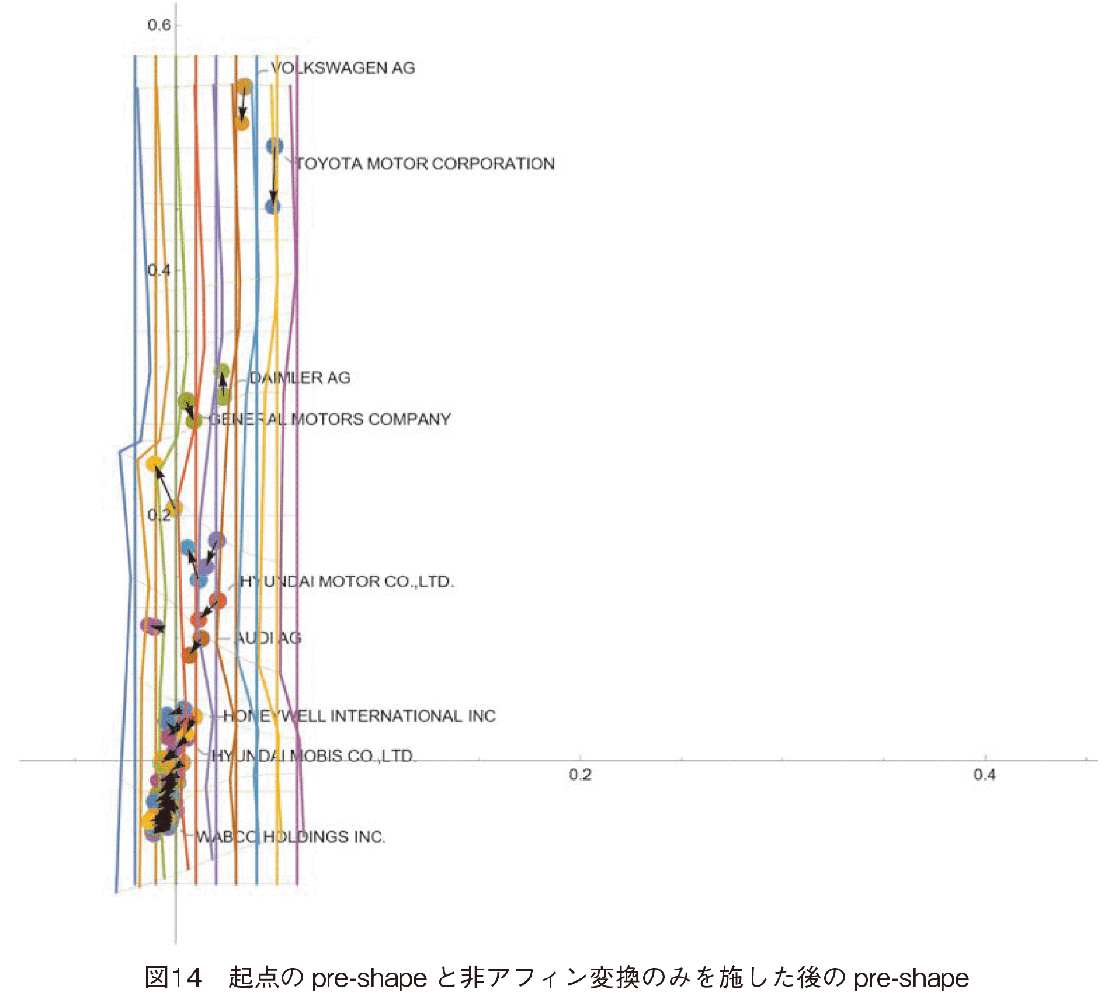
【156頁】 ルには,売上高が減少していることを意味する。非アフィン変換のみの変化全体を見ると,売上高が高いエリアと低いエリアでは,売上高の局所的減少傾向が見られ,売上高の中間エリアでは,売上高の局所的増加傾向が見られる。もちろんGMのように中間エリアに位置しても売上高減少を示す例外はある。
それでは,具体的にはどの企業が局所的に見て売上高増加であったのかを,非アフィン変換の差分のみを抽出して見てみよう(図15参照)。STELLANTIS,SAIC, DAIMLER,BAIC, VOLVOが売上高を増加させていたことが分かる。これは周囲に対しての相対的な増加である。例えば,STELLANTISはアフィン変換では売上減少エリアにいるが,それに比較すると売上増加である,という意味である。トップ2社のアフィン変換及び非アフィン変換を合併しての動きを見ると,若干売上高が減少している。これはpre-shapeの動きを見ているので,業界全体として若干,売上高における差が縮小したことを意味する。

まとめると,全体的な傾向としては売上高が増加した。その中で局所的な動きを見ると,売上高の中間層にいた企業が相対的に売上高を伸ばした,と言える。
【157頁】
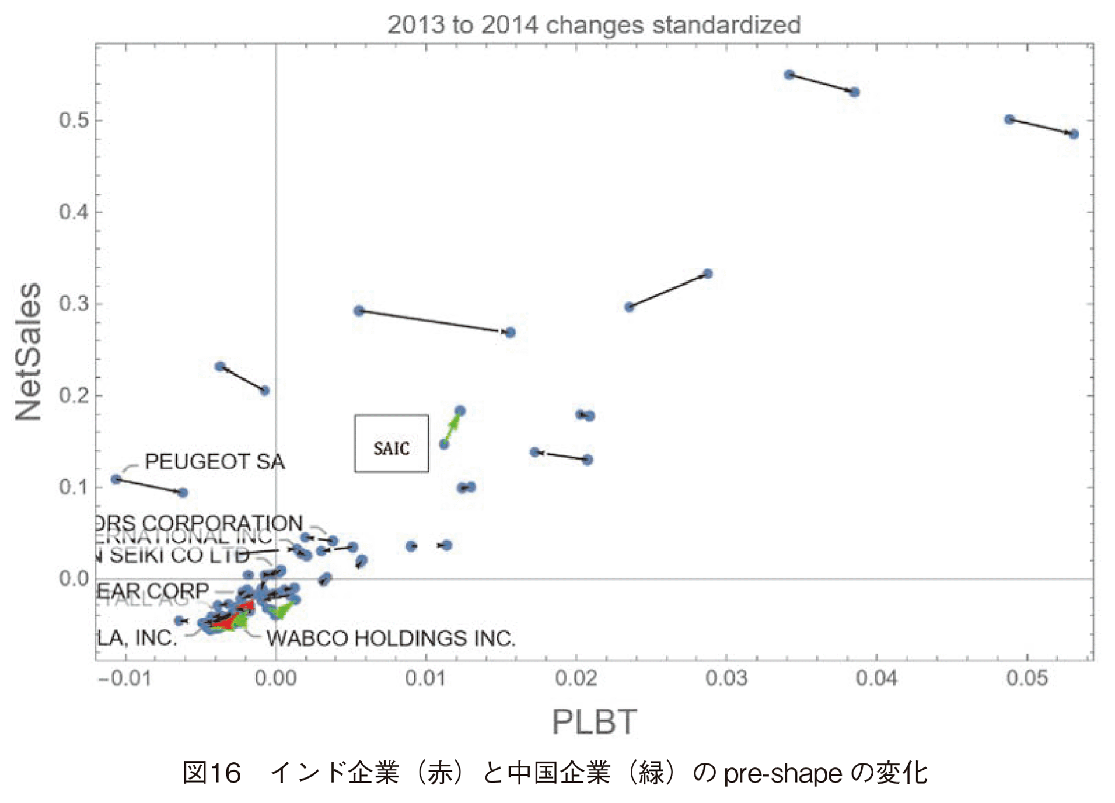
4.4 インドと中国企業の変化
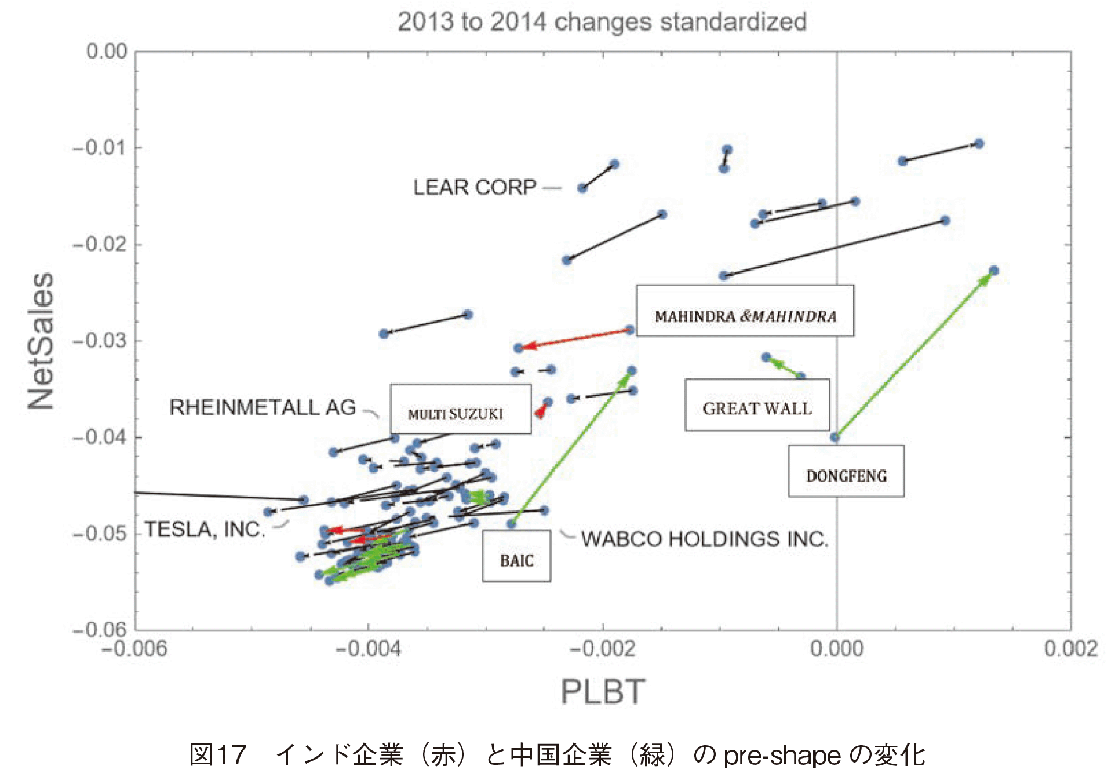
第3節では,インドと中国企業の株価が急上昇していたことが分かった。それでは,インドと中国の企業の規模は全体の中でどの位置にあったかをshape analysisで見ていこう。図16と図17に,全企業の2013年と2014年のpre-shapeの変化を示した。図中,インド企業を赤矢印,中国企業を緑矢印で示した。図16を見ると,SAICが全体の中で,PLBT,売上高ともに規模が大きいことが分かる。他のインド企業,中国企業は規模が小さく左下の集団の中に存在し,変化率も全体の中で小さい。図16の左下集団を拡大した図を図17に示した。中国企業ではDONGFENG,BAICが売上高を大きく伸ばしていることが分かる。インド企業の中ではMAHINDRA&MAHINDRA LIMITEDがPLBT,売上高ともにトップである。しかし,全体の成長のフォーメーションの中では,PLBTは相対的に伸び悩み,売上高ではほぼ横ばいであることが分かる。それに比較して,MULTI SUZUKIは,PLBT,売上高ともに若干ではあるが,正の方向に伸ばしている。他のインド企業は負の方向に伸びているが,これは成長はしているが,全体の成長の速度に比較して伸びが十分ではない,ことを示している。
前3節では,インド企業及び中国企業の株価上昇率が高いという結果が得られたが,本節のshape analysisで得られた結果は,インド及び中国企業のPLBT及ぶ売上高の規模は全体の中では小さいということである。この2つの結論をまとめると,インド及び中国企業は全体的の売上高ランキングでは上位ではないが,その株価上昇率は,売上高ランキング上位の企業を抜いて高かった,と言える。インドと中国の本事例から考えるに,規模が小さい企業の方が,株価上昇率を向上させるのは容易である,と考えられる。
【158頁】
5.まとめ
世界自動車製造企業の2014年度の変化を分析した。まず,1年間の株価変動パターンを機械学習のAmplitude-basedクラスタリング手法によって分析した。その結果,インド企業及びパキスタン企業の株価が急上昇するパターンが検出できた。インド企業に次いで株価を急上昇させたクラスター中には,中国企業3社があった。時系列データクラスタリングではなく,単純に最終的な株価上昇率を見ると,1.7倍以上にインド6社,中国12社が含まれていた。
次に,2013年度と2014年度のPLBTと売上高の変化の様子をshape analysis手法によって分析した。本手法の特長は,2次元散布図で表されるフォーメーションの変化を,pre-shapeという標準化した形式で表現すること,及び,2つのpre-shape間の変動を,アフィン変換と非アフィン変換に分けられることである。これにより,全体的な変動だけではなく,データ固有の局所的な変動を数値表現によって客観的に評価可能としたことである。得られた結果としては,PLBTよりも売上高成長率の伸びのほうが大きかった。アフィン変換では売上高成長率は全体として増加傾向であることを示したが,非アフィン変換では,TOYOTA,VWという売上高1位2位の企業では,局所的に下落が見られた。これは,全体としてはどの企業も成長しているが,上位の企業は容易には成長できず,全体としては差が縮まったことを示す。インドと中国企業の全体の中での位置は,PLBT,売上高ともに,平均を下回る位置が多かった。中国企業では,SAICが規模ともにNo1で売上高も大きく増加している。ついで,DONFENG, 【159頁】 BAICの伸びが顕著であった。インド企業では,売上高規模ではMAHINDRA & MAHINDRAが第1位であり,株価上昇パターンも顕著であったが,全体の成長傾向の中では,PLBTにおいて負の変化を示した。MULTI SUZUKIは,若干正の変化を示した。Shape analysisで負の変化を示したが,株価上昇率は大きく伸ばしたという特徴をもつインド企業及び中国企業は,規模が小さい間は株価上昇が容易である,という一般的傾向を示すものと考えられる。世界自動車製造業の動向分析では,売上高等が大きい規模の大きな企業の変化に注目が集まりがちであるが,2014年においては,SAICだけではなく,インド及び中国企業が大いに株価を上昇させていたことが分かった。
参考文献
[1] Y. Shirota, K. Kuno, and H. Yoshiura, "Time Series Analysis of SHAP Values by Automobile Manufacturers Recovery Rates," in 2022 6th International Conference on Deep Learning Technologies (ICDLT), 2022: ACM.
[2] M. Fujimaki, E. Tsujiura, and Y. Shirota, "Automobile Manufacturers Stock Price Recovery Analysis at COVID-19 Outbreak," in 6th World Conference on Production and Operations Management - P&OM Nara 2022, Nara, Japan, 2022, p. in printing: EurOMA (European Operations Management Association).
[3] 日本経済新聞・日経クロステック合同取材班,Apple Car デジタル覇者vs自動車巨人.2021.
[4] Y. Shirota and B. Chakraborty, "Amplitude-Based Time Series Data Clustering Method," Gakushuin Economics Papers, vol. 59, no. 2, 2022.
[5] I. L. Dryden and J. T. Kent, Geometry driven statistics. John Wiley & Sons, 2015.
[6] J. Paparrizos and L. Gravano, "k-shape: Efficient and accurate clustering of time series," in Proceedings of the 2015 ACM SIGMOD international conference on management of data, 2015, pp. 1855-1870.
[7] J. Paparrizos and L. J. A. T. o. D. S. Gravano, "Fast and accurate time-series clustering," vol. 42, no. 2, pp. 1-49, 2017.
[8] F. Petitjean, A. Ketterlin, and P. J. P. r. Gancarski, "A global averaging method for dynamic time warping, with applications to clustering," vol. 44, no. 3, pp. 678-693, 2011.
[9] S. Aghabozorgi, A. S. Shirkhorshidi, and T. Y. J. I. S. Wah, "Time-series clustering-a decade review," vol. 53, pp. 16-38, 2015.
[10] H. Ito, A. Murakami, N. Dutta, Y. Shirota, and B. Chakraborty, "Clustering of ETF Data for Portfolio Selection during Early Period of Corona Virus Outbreak," Gakushuin Journal of Economics, vol. 58, no. 1, pp. 99-114, 2021.
[11] Y. Shirota and B. Chakraborty, "Automakers Stock Price Movement Comparison under COVID-19," in 2021 International Conference on Data Analytics for Business and Industry (ICDABI), 2021, pp. 375-379: IEEE.
[12] M. L. J. T. J. o. P. M. De Prado, "Building diversified portfolios that outperform out of sample," vol. 42, no. 4, pp. 59-69, 2016.
[13] M. L. De Prado, Advances in financial machine learning. John Wiley & Sons, 2018.
[14] M. M. L. de Prado, Machine learning for asset managers. Cambridge University Press, 2020.
[15] グルチャラン・ダス,日本人とインド人 世界市場「最後の成長エンジン」の真実.プレジデン 【160頁】 ト社,2020.
[16] 松本勝男,インドビジネス ラストワンマイル戦略 SDGs実現は農村から.日本経済新聞出版,2021.
[17] I. L. Dryden and K. V. Mardia, Statistical shape analysis: with applications in R. John Wiley & Sons, 2016.
[18] Y. Shirota, A. Presekal, and R. F. Sari, "Visualization of Time Series Change on GDP Per Electricity by Provinces in Indonesia," in 2018 International Electronics Symposium on Knowledge Creation and Intelligent Computing (IES-KCIC), 2018, pp. 328-331: IEEE.
[19] A. Presekal, R. F. Sari, and Y. Shirota, "Local change analysis of correlation of education level to GDP in Indonesia," Gakushuin Economics Papers, vol. 55, no. 3, pp. 61-77, 2018.
[20] Y. Shirota, R. F. Sari, and T. Hashimoto, "Time series analysis on Indonesia Provinces economic development," in Proc. 5th Conference on Management and Sustainability in Asia, 2018, pp. 12-19.
[21] T. Widiyani, Y. Shirota, and R. F. Sari, "A morphometries analysis method for craniofacial differences of ancient humans," presented at the Prof. of 2nd International Conference on Automation, Cognitive Science, Optics, Micro Electro Mechanical System, and Information Technology (ICACOMIT), Jakarta, 2017.
[22] Y. Shirota, T. Hashimoto, and R. F. Sari, "Visualization of time series statistical data by shape analysis (GDP ratio changes among Asia countries)," in Journal of Physics: Conference Series, 2018, vol. 971, no. 1, p. 012013: IOP Publishing.
[23] Y. Shirota, T. Hashimoto, K. Yamaguchi, and R. F. Sari, "Time Series Analysis of Gender Empowerment Index by Provinces in Indonesia," 東洋文化研究,Journal of Asian cultures, no. 23, pp. 304-283, 2021.
[24] Y. Shirota, R. F. Sari, T. Widiyani, and T. Hashimoto, "Visually do statistical shape analysis! As TUTORAL," in Data Science and Advanced Analytics (DSAA): IEEE, 2017.
[25] 白田由香利,橋本隆子,佐倉環,and 久保山哲二,"幾何学的統計学の可視化教材の作成,"学習院大学計算機センター年報,no. 39,pp. 2-10,2018.