���_�ɂ��f�[�^���͂ɂ�����ChatGPT�̊��p
�w�K�@��w�o�ϊw���o�c�w�ȁ@�@���c�R����
���w����ɂ����ĉ�@�ߒ��ɂ����鐄�_�̗͂{���͏d�v�ƍl����B�M�҂́C�o�c���w����ɂ����鐄�_�̏d�v���������C��㈐��_���j�Ƃ���u�`���s���Ă����B���݁C���猻��ɂ�����ChatGPT�̊��p�ɋc�_���N�����Ă���B�{�e�ł́CChatGPT�ɂ�鐔�w����@�ɂ�����C���_�ł�ChatGPT�̊��p�ɂ��Ę_����BChatGPT�̋@�\�̒��ŁC�M�҂��ł����p���ׂ��ƍl�����@�\�̓v���O�����̒@�\�ł���B�v���O���~���O�}�j���A�����Q�Ƃ����Ԃɔ�r���āCChatGPT�ւ̎���̂ق����C���ԂƎ�Ԃ����Ȃ��C����҂̈Ӑ}�ɍ��v����������邱�Ƃ������Ɗ�����B����ChatGPT�̋@�\�����p�\�Ȑ��w���番��́C�f�[�^���͎�@�̊w�K�ƍl����B�{�e�ł́C�f�[�^���͎�@�̊w�K�ɂ�����w�K�҂̐��_�ɁCChatGPT���ǂ̂悤�Ɋ��p�ł��邩��Ă���B�f�[�^���͎�@��������ۂɁC��㈉ߒ������ĂƂ��Ď����C����ǂ��ĉ�㈂��s�����ƂŊw�K��i�߂Ă��炤�B�f�[�^���͂ɂ����ẮC�X�e�b�v���Ƃɓ��o���ꂽ���ʂ̉������s�����Ƃ��L�v�ł���B�]���́C�����Ńv���O������������Ԃ��傫���������߁C�����ɂ�錋�ʌ����X�L�b�v���Đ�ɐi�߂邱�Ƃ����������BChatGPT�̊��p�ɂ������v���O�������e�Ղɍ쐬�\�ƂȂ�C���͎�@�ɗ������[�܂�C���͌��ʂ̌����e�ՂƂȂ�C���ʂƂ��Ď����̃v���O�����̊ԈႢ�y�ъT�O�̗����̊ԈႢ�ɂ��C�Â����Ƃ��e�ՂƂȂ�B�{�e�ł́CChatGPT�����p���ĉ�㈂��邱�ƂŃf�[�^���͎�@���w�K������w�K�������Ă���B���̎���Ƃ��Ď听������PCA���w�K���鉉㈉ߒ��������B
���w����ɂ����ĉ�@�ߒ��ɂ����鐄�_�̗͂{���͏d�v�ƍl����B�M�҂́C�o�c���w����ɂ����鐄�_�̏d�v���������C���_���j�Ƃ���u�`���s���Ă����B�^����ꂽ�f�[�^���疢�m���Ɏ��鉉㈐��_�ߒ�����@�v�����O���t�Ƃ��Ċw���ɒ��C��@����㈐��_�ߒ��Ƃ��ċ����Ă����B��@�v�����O���t��������������V�X�e�����쐬���C�L�x�ȃh�������̐��Y�ɍv�������B���݁C���猻��ɂ�����ChatGPT�̊��p�ɋc�_���N�����Ă���m�P�n�m�Q�n�B�{�e�ł́CChatGPT�i�ȍ~ GPT�Ɨ����j�ɂ�鐔�w����@�ɂ����鐄�_�ɂ�����GPT�̊��p�ɂ��Ę_����BGPT�̋@�\�̒��ŁC�M�҂��ł����p���ׂ��ƍl�����@�\�̓v���O�����̒ł���B�v���O���~���O�}�j���A�����Q�Ƃ����Ԃɔ�r���āCGPT�ւ̎���̂ق����C���ԂƎ�Ԃ����Ȃ��C����҂̈Ӑ}�ɍ��v����������邱�Ƃ������Ɗ�����B����GPT�̋@�\�����p�\�Ȑ��w���番��́C�f�[�^���͎�@�̊w�K�ƍl����B�{�e�ł́C�f�[�^���͎�@�̊w�y180�Łz �K�ɂ�����w�K�҂̐��_�ɁCGPT���ǂ̂悤�Ɋ��p�ł��邩��Ă���B��Ă���w�K�@�́C�f�[�^���͎�@�̊w�K�ɂ����鉉㈐��_�@�ł���B�f�[�^���͎�@��������ۂɁC��㈉ߒ������ĂƂ��Ď����C���������ǂ��ĉ�㈂��s�����ƂŁC�w�K��i�߂�B�f�[�^���͂ɂ����ẮC�X�e�b�v���Ƃɓ��o���ꂽ���ʂ̉������s�����Ƃ��L�v�ł���B�]���́C�����Ńv���O������������Ԃ��傫���������߁C�����ɂ�錋�ʌ����X�L�b�v���Đ�ɐi�߂邱�Ƃ����������BGPT�̊��p�ɂ������v���O�������e�Ղɍ쐬�\�ƂȂ�C���͎�@�ɗ������[�܂�C�����e�ՂƂȂ�C���ʂƂ��Ď����̃v���O�����̊ԈႢ�y�ъT�O�̗����̊ԈႢ�ɂ��C�Â����Ƃ��e�ՂƂȂ�B
���߂ł́C�M�҂��s���Ă�����㈂ɂ�鐔�w�w�K�@�ɂ��ĊT������B��R�߂́C����W�����āCGPT�����p���ăf�[�^���͎�@���w�K������Ƃ����o�[�W�����̊w�K�������Ă���B��S�߂́C���̎���Ƃ��Ď听������PCA���w�K���鉉㈉ߒ��������B��T�߂͂���Ɋւ���l�@�ł���C��U�߂͖{�e�̂܂Ƃ߂ł���B
�{�߂ł́C�M�҂��l�Ă����H���Ă��鉉㈐��_�@���ȒP�ɐ�������B�ڍׂ́m3-13�n���Q�Ƃ��Ē��������B
�M�҂́C�o�c���w����ɂ����鐄�_�̏d�v���������C�u�`�ɂ����Ă��C��㈉ߒ�����@�v�����O���t�Ƃ��Ċw���ɒ��C���_�͗{����ڕW�Ƃ��鐔�w������s���Ă����B�����āC��@�v�����O���t��`���c�[���Ƃ��āC��@�v�����O���t�E�W�F�l���[�^�Ƃ����V�X�e�����J�����C��@�v�����O���t���ނ𑽐��쐬���C����ɗp���Ă����B��@�v�����W�F�l���[�^�̃V�X�e���\�z�ƕ]���ɂ��Ắm3�C13�n���Q�Ƃ��Ē��������B
�M�҂̏����ڕW�́C�w�K�x���V�X�e���ie-Learning �V�X�e���j�ɂ����āC���x�Ȑ��_�x���@�\���������邱�Ƃł���B���̂��߂ɂ́C�l�Ԃ̊w�K�҂��ǂ̂悤�ɐ��_���s���Ė��������Ă��邩�C�l�@����K�v������̂ŁC�ȒP�ɐ�������B
���_�ɂ́C��㈁C�A�[�C�A�u�_�N�V�����̂R��ނ�����m14�n�B��㈂ł́C�O������C�_���w�̋�����K���ɏ]���Č��_�o����B�R�i�_�@�́C��㈂ł���B��㈂͘_���I�ɉ��肵���闝�z��Ԃ��`���I�ɐ}���I�ɕ\�ӂ��C���̗��z��Ԃɂ����鎖�ہi�_���I�Ώہj�̊Ԃ̕K�R�I�W����������L���ߒ��ł���m15�n�B���w�̗�Ō����ƁC�A���������������ĉ������߂�ߒ��́C��㈂ł���m15�n�B���߂������m���i���_�j�́C�^����ꂽ���Ɋ��ɈÁX���Ɋ܈ӂ���Ă��āC�A���������������`���I�葱���ɂ���āC���m����������邩��ł���B�A�u�_�N�V�����͌ʂ̎��ۂ��ł��K�ɐ��������鉼���o���鐄�_�ł���C���ۊԂ̈��ʊW�̉𖾂ɏd����u���m16�n�B
�p�[�X�iCharles Sanders Peirce�j�̓A�u�_�N�V�����̐��_�`�����C�ȉ��̂悤�ɒ莮�����Ă���m15�n�F�����ׂ�����C���ώ@�����B����������H���^�ł���CC�͓��R�̎����ł��낤�C����āCH���^�ł���ƍl����ׂ����R������BC�Ƃ́C��X�̋^�O�ƒT���������N��������ӊO�Ȏ����܂��͕ϑ����̂��Ƃł���CH��C��������邽�߂ɍl����ꂽ�����ł���B�A���C�A�u�_�N�V��������ыA�[�@�ɂ����ẮC�O�^�ł����Ă��������^�ł���Ƃ͌���Ȃ��B
�y181�Łz�o�όo�c���w�̖��̖w�ǂ́C�ؖ����ł͂Ȃ��C���m���̒l���i�v�Z�j����^�C�v�̖��ł���B����āC�����̖��ɂ����ẮC���ŗ^����ꂽ�f�[�^�iGiven Data�j���牉㈂����邱�ƂŁC���ʂƂ��āC���m���iUnknown�j�̒l�����߂�m23, 24�n�B���߂������m���́CGiven Data�C�����C�Z�I���[��O��Ƃ��āC��㈂��s���CUnknown�����_�Ƃ��ē��o�\�C�ƌ�����B Given Data ���� Unknown �ɓ��鉉㈉ߒ���}�I�ɕ\�������@�Ƃ��āC��X�͐}�P�̂悤�ȕ\�����Ă����B���̉�㈉ߒ�����X�́u��@�v�����O���t�v�ƌĂ�ł���B
�����������Ƃ���ہC��X�͎n�߂���C��@�v�����O���t�̂悤�ȉ�㈉ߒ������ɕ����Ԃ킯�ł͂Ȃ��B�A�u�_�N�V�����ɂ���āC��㈉ߒ��̓r���r���ɂ����ĉ�����n�����C���̉������b��I�ɍ̑����邱�ƂŁC�X�e�b�v�ɕ����Đ��_���s���ƍl������B���̍ۂɂǂ̂悤�ȃX�e�b�v���������邩�C����͂Ȃ����C��X�́C�l���o�c���w�����������_�ߒ��͈ȉ��̂悤�Ȃ��̂ł���ƁC�l�����B �o�c���w�����������߁C�l�́C��㈁C�A�[�C�A�u�_�N�V�����̂��ׂĂ��I�ɋ�g���Ďv�l���s���Ă���ł��낤�B���̏ڍׂ͒肩�ł͂Ȃ����C�l�͂��̎v�l�̉ߒ��ɂ����āC�A�u�_�N�V�����ɂ���āC����H�𗧂ĂĈ�����\�����Ȃ���CUnknown ���� Given Data �����ɂނ����āC�܂��t�����ɉ�㈐��_��K�����āC�ׂ����X�e�b�v�ɕ����Ė��������Ă���̂ł͂Ȃ����낤���B�|�C���g�́C�t�����ɐ��_����C�Ƃ����_�ƁC�A�u�_�N�V�����ɂ�蕔���ڕW��ݒ肷�����Ƃł���B���̃A�u�_�N�V�����̍ہC�����̉����̒�����C�ł������Ƃ��炵��������I�Ԃ��Ƃ��d�v�ł��邪�C����́C���̎��_�ŗ^����ꂽ�f�[�^�ƌv�Z�ς݃f�[�^�C����ђm���Ă����������уZ�I���[����g���Đ�������B�l�����̂悤�ɐ��_����Ɖ��肵���ꍇ�Ce-Learning �V�X�e���\�z�ɂ����Ă��C���̃v���Z�X���w���v����悤�ȋ@�\����������C�w���̊w�K�Ɍ��ʂ�����̂ł͂Ȃ����낤���C�ƍl�����B
���ɋ�̓I����������B
��X�́C�c���N���Q�N�C�N�[�|���E���[�g2.00���C�����̉��i�i�z��100�~������j100.00 �~�C�}�R�[���[�E�f�����[�V������1.98�N�C�C���f�����[�V������1.94�C�R���x�L�V�e�B5.69�C�N�[�|���̎x�������N�P��̍��ł���B�����̍ŏI�����i�N�P���j��2.00���ł���C�����͗�����������ł���B�X�|�b�g�E���[�g�E�J�[�u�͐����Ɖ��肷��B�����C�X�|�b�g�E���[�g���P���ቺ���āC���̂܂܂P�N�Ԍo�߂����Ƃ���B�����������i���C�ߎ������g���ċ��߂Ȃ����B��X�ɍ�������P�N�ԓ��������ꍇ�̓������^�[���͉����ɂȂ�܂����B
�y182�Łz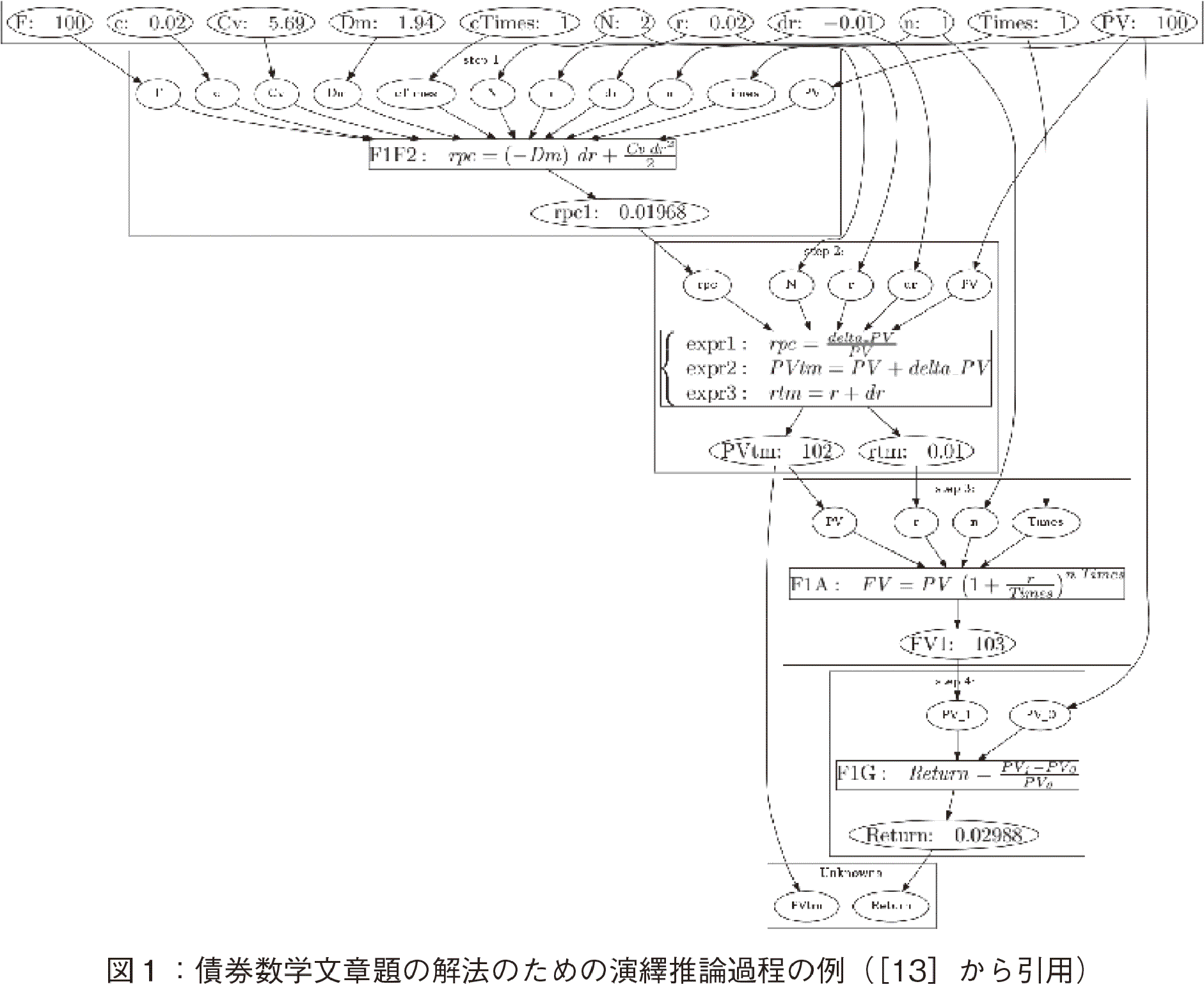
�}�P�ɖ{���͑���������߂̉�@�v�������������B�l�p�������i�����j��\���C�ȉ~�`�͕ϐ��l��\���B���̖����������߁CUnknown�ł���u���^�[���l�v����̋t�������_���s���Ƃ悢�ł��낤�i�}�P�̈�ԉ��̎l�p�j�B���̂��߂ɂ́C�����̍����iPV�iPresent Value�j����сC�P�N��̏������l FV�P�iFuture Value 1�j�����߂�K�v������istep�S�j�B�����ϓ��ɂ��C�����Ɩ����̋����i�X�|�b�g�E���[�g�j�̍��́C�P���̒ቺ�ƁC���͂ɋL�ڂ���Ă���B�����ŁC�u�����̍����iPVtm ���v�Z�ł���C�P�N��̍��̏������lFV1���v�Z�ł��邱�Ƃ͓��R�̎����ł��낤�v�Ƃ������������Ă���istep�S�j�B�u�����Ɩ����̍����i�̍������v�Z�ł���̂ł���C�����̍����iPVtm���v�Z�ł��邱�Ƃ͓��R�̎����ł��낤�v�istep�R�j�B�܂��C�u���i�ω���rpc ���v�Z�ł���̂ł���C�����Ɩ����̍����i�̍����v�Z�ł��邱�Ƃ͓��R�̎����ł��낤�v�istep�R�j�B�܂�CPVtm�����߂邽�߂ɂ́C���i�̍���dPV���K�v�ł��邪�C����͉��i�ω��� rpc �̌�����p���邱�ƂŌv�Z�����ł��낤�istep�R�j�C�Ɛ�������B����rpc���v�Z���邽�߂Ɍ���F1F2�̃e�C���[�W�J�̌������g���悢�ł��낤�istep�P�j�B����F1F2��p����rpc�����߂邽�߂ɂ́C�ق����f�[�^PV, Dm, Cv��������Ă��邩�����ƂȂ�CGivenData���m�F����ƁC�͂����āCPV, Dm, Cv�̒l�͗^�����Ă����B���̂悤�ȋt�����̐��_���s����C�ƍl���邱�Ƃ͂����Ƃ��炵���B���̉�@�ɂ�����ł��d��ȂЂ�߂��Ƃ�����ׂ������́Cstep�R�́u���i�ω���rpc���v�Z�ł���Ȃ�C�����y183�Łz �i�̍���dPV���v�Z�ł��邱�Ƃ͓��R�̎����ł��낤�v�ł��낤�B�����̊w�������Ă���ƁC���̐��_���ł��Ȃ��w���������B�����āCrpc��Given Data���g���ċ��߂��邩�������C���̌��ʁC���߂��邱�Ƃ���������Brpc�����߂�ꂽ�̂ŁC��㈂ɂ���āCdPV�����߂���C�ƂȂ�B
����step�P�ɑ������鉼���̐ݒ�ɂ����āC��X�͎��s����I�ɉ������l���Ă���B�������C���̍ۂɂ́C���闝�R�������āC�������鉼���̒�����ł������Ƃ��炵��������I�����Ă���B�Ⴆ�C���͑�Ƃ��āC�C���f�����[�V��������уR���x�L�V�e�B�̒l���^�����Ă���̂ŁCrpc�̌��������Ȃ��Ƃ��ǂ����Ŏg���̂łȂ����ƁC����l�͐�������ł��낤�B�����̏ꍇ�C�t�����ɐ��_���s���邪�C�t�������@����̂ݐ��_���s����킯�ł͂Ȃ��C���̐l�̉ߋ��̌o���Ȃǂ���C�����ڕW���ݒ肳�ꂤ��̂ł��낤�B����step�P�̐��_ �́C�@�B����݂����ɉ�����������̂ƈႢ�C�l�Ԃ������C���e���W�F���X�������Đ��_�����Ă���\����������ł���
���̕����Ɋ�Â��o�όo�c���w���ȏ����M�҂͏����m17�n�A���H���Ă���m12�n�B���C���^�[�Q�b�g�͌o�όo�c���w�̎��Ƃł���C�����ł�IS-LM���C���v�����ɌW����C�œK�����Ȃǂ������B��ʓI�Ȍo�όo�c���w���ȊO�ɂ��L���{������K�����Ă���B
�M�҂́C��㈐��_�ɂ�鐔�w���͑��@�������w����ɂ����p�����B�����w�Ɋւ���������������C�����w�̊T�O���f�����\�z�����m�X�n�B�{�T�O���f���́C���̊W�iE-R�j�_�C�A�O�����ŕ\�킳��C���̃_�C�A�O�������Unknown����GivenData�Ɏ��鉉㈉ߒ��̃p�X�����邱�ƂŁC�w�K�҂�Unknown�����߂�B���̊T�O���f�������ŁC�w�ǂ̍����w�̋��ȏ��ɂ��镶�͑肪�����邱�Ƃ��������m�X�n�B
�܂��C�V���v���E�g�s�b�N�E���f���̃x�C�Y���_�̉ߒ��o���鉉㈐��_�ߒ�����@�v�����O���t�ɂ�莦�����m�T�C�U�n�B
�܂��CGivenData����Unknown�܂ł̃p�X�����ɕ��G�Œ�����Ƃ��āC�u���b�N�V���[���Y�̌��������߂�C�Ƃ�����㈐��_�ߒ����������i�}�Q�Q�Ɓj�B�M�҂́C�u���b�N�V���[���Y��������{��@�v�����O���t��p���ċ����Ă���m18�n�B�u���b�N�V���[���Y�������̓��o�͒����̂ŁC�w�K�҂͍��ǂ̌������������ĉ�㈂��Ă���̂���������Ȃ��Ȃ�₷�����C��@�v�����O���t��n�}�Ƃ��āC���݂̐��_���ǂ��̕����Ɉʒu����̂���������Ƃ������_������B
�y184�Łz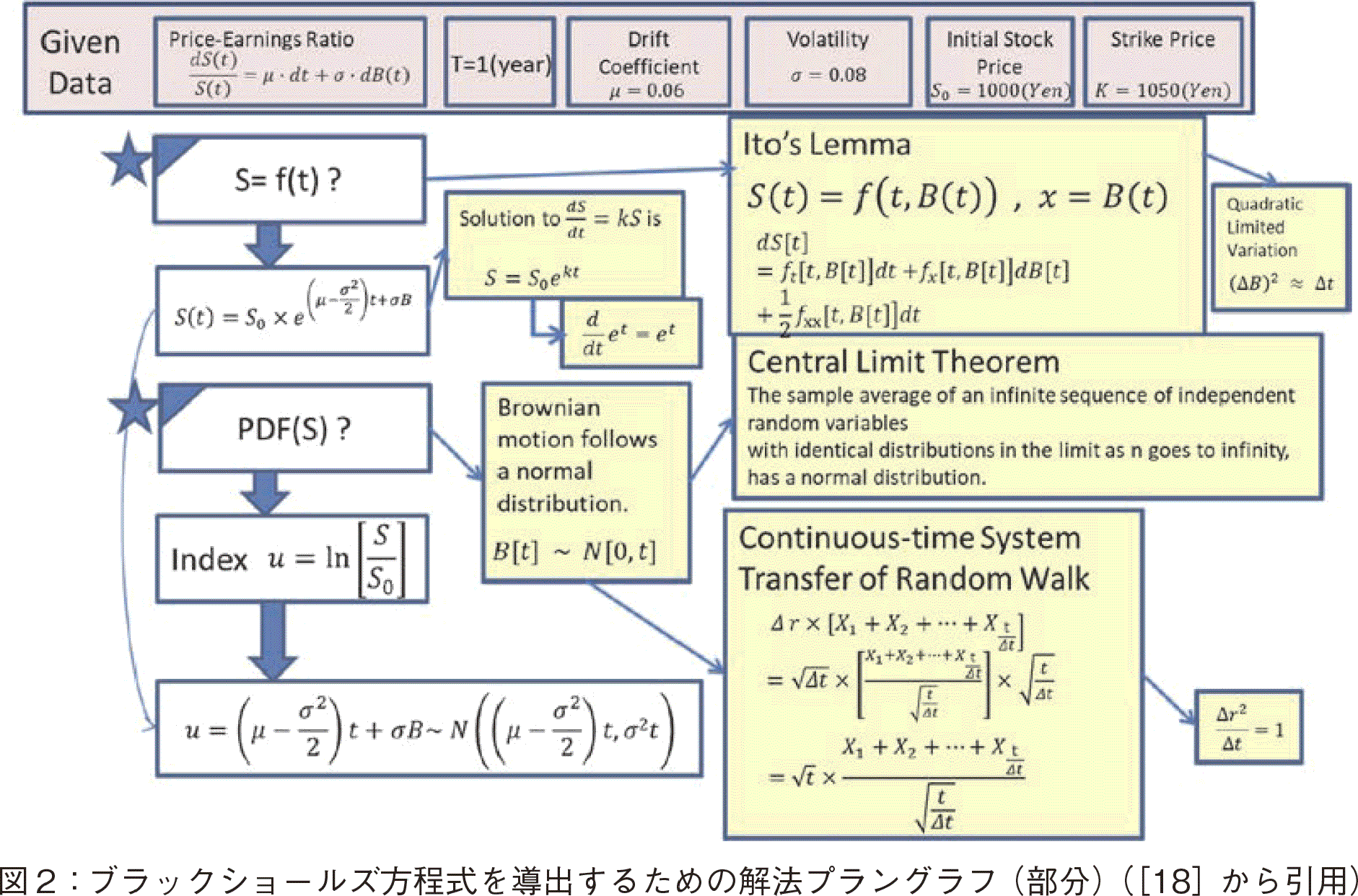
�{�߂ł͐V���ɁC��㈐��_�ɂ��f�[�^���͊w�K�@���Ă���B�Ώۂ́C�f�[�^���͎�@�̊w�K�ł���B�l�Ԃ̋��t���\�ߍu�`���s���C���̒m���蒅�̂��߁C�w�K�ҁi�w���j�͓ƏK���s�Ȃ��C�ƏK�ɂ����Ċw�K�҂�GPT�����p����C�Ɖ��肷��B�ȉ��̃v���Z�X�Ŋw�K�͐i�ށB
�i�P�j�l�Ԃ̋��t���������쐬���C�w�K�҂ɒ���B���Ă͉�㈐��_�ɂ��GivenData����Unknown�Ɏ���p�X�Ƃ��Ď�����Ă���B
�i�Q�j�w�K�҂�GivenData����Unknown�����ɉ�㈂��s�Ȃ��Ȃ���w�K��i�߂�B�e�����́C�v���O�������s�ɑΉ�����B���̓f�[�^���v���O�����ɓ��͂��C�o�̓f�[�^��B�����Ď��̉�㈐��_�ɐi�ށB���̃v���O�����쐬��GPT���g���BGPT�Ɏ��₷�邱�ƂŁC�v���O������Ԃ��Ă��炢�C���̃v���O���������s����B�z�肵�Ă���v���O���~���O����̓p�C�\���ł���B
�i�R�j���ĂƈႤ���ʂ�����ꂽ�ꍇ�C�w�K�҂͂����ꂩ���s���B
�i�A�j�������e�̎�������t��ς��čs���CGPT���������v���O������Ԃ��܂ŌJ��Ԃ��B
�i�C�j�Ԉ�������R�������ŃA�u�_�N�V��������B�A�u�_�N�V�����̉������v�����Ȃ��ꍇ�CGPT�Ɏ��₵�C�A�u�_�N�V�������x�����Ă��炤�B
�i�S�j��㈌��ʂ̃f�[�^�̌��̂��߁C�O���t�E�v���b�g����B�v���b�g�̂��߂̃v���O������GPT�Ɏ��₵�ċ����Ă��炤�B
�y185�Łz�z�肵�Ă���f�[�^���͎�@�́C�L�����y���Ă����@�C�Ⴆ�C��A���́C�N���X�^�����O�C�������k�C�Ȃǂ̌͂�Ă����@��z�肵�Ă���B�����GPT��web��̏W���m����ɉ��쐬���Ă���̂ŁC���y���Ă���f�[�^���͎�@�łȂ��ƃv���O������Ȃǂ�web��ɑ��݂��Ȃ�����ł���B���߂ł́C��̓I�Ȋw�K�̐i�ߕ���������B
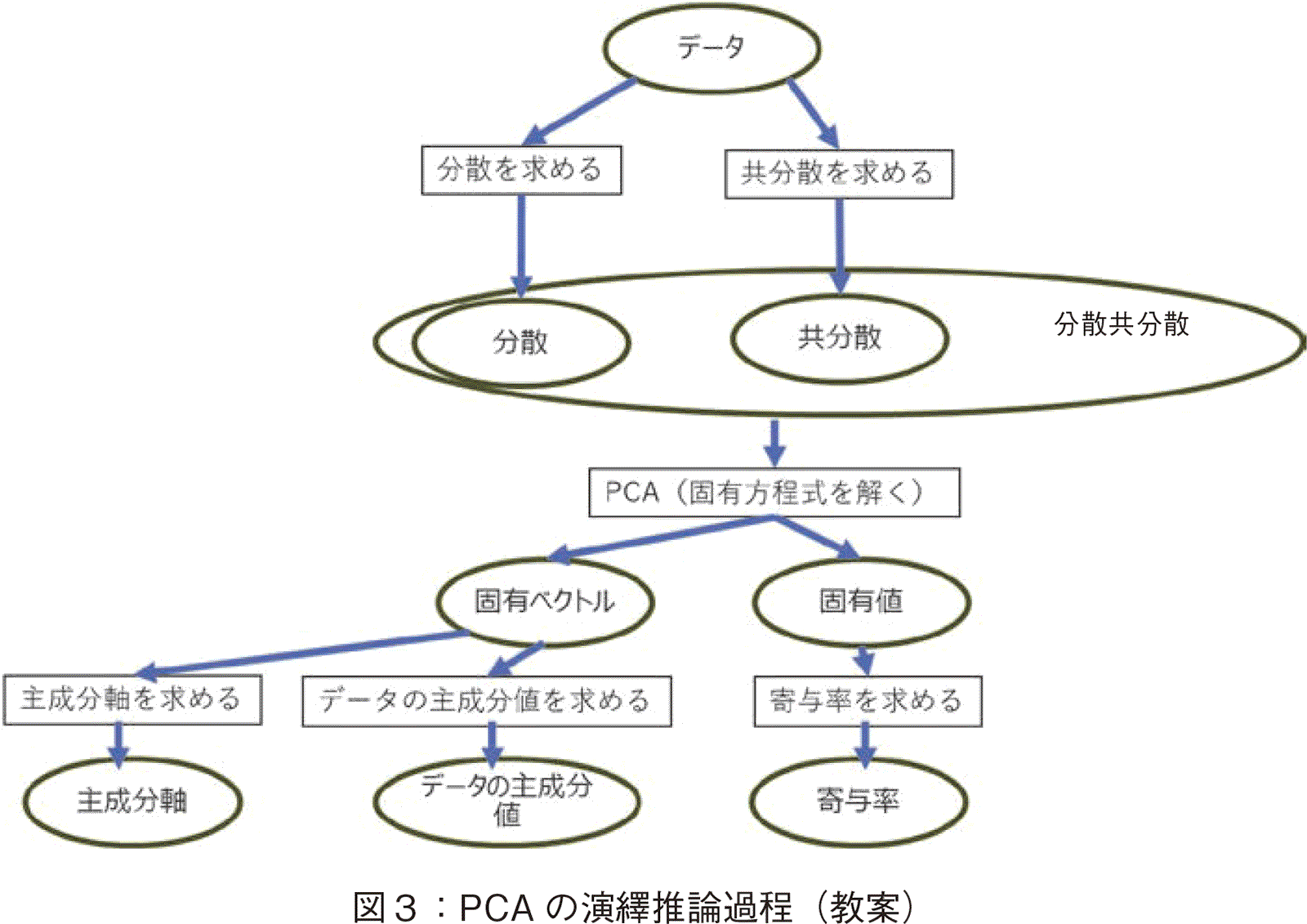
�{�߂ł́C��㈐��_�ɂ��f�[�^���͎���Ƃ��āC�听�����́iPCA�j�ɂ��f�[�^���͂�GPT�Ƃ̑Θb��ʂ��Ċw�K���鎖����Љ��B�{������g���āCGPT���p�̌��ʂ��������B
PCA�͋��t�Ȃ��w�K���s���C�f�[�^�̎听���𒊏o����m19�n�m20�n�BPCA�̓m�C�Y�̑����f�[�^�̃t�B���^�����O��i�Ƃ��ė��p�ł��C��^�x�̑傫�Ȏ听���݂̂�I�����C�f�[�^���č\�z����C�m�C�Y���������f�[�^�̖{���I���i�𒊏o���邱�Ƃ��\�ƂȂ�m21�n�B�f�[�^�́C�C���h�l�V�A�́u���Z�A�w���i2020�N�x�j�v�y�сu�g�ѓd�b���y���i2022�N�x�j�v�̏B�ʃf�[�^�Ƃ���B�f�[�^����31�i�B�j�ł���B�{�f�[�^�̓C���h�l�V�A���v�ǂ̃T�C�g���猟�������ihttps://www.bps.go.id/�j�B
PCA���͂ɂ����ẮCGivenData����L�B�ʃf�[�^�CUnknown���Q����C�i�P�j�e�f�[�^�̎听���l�Ɓi�Q�j�听���̊�^���Ƃ���BGivenData����Unknown�Ɏ��鉉㈐��_�ߒ��i���āj��}�R�Ɏ����B�}���C�l�p�`�͗p����������邢�͎葱���������C�ȉ~�`�͂��̉��i�l���邢�͐����j�������B���̐��_�ߒ��́C�w���ɗ\�ߗ^�����C�w���͂����p�������w�̍u�`���Ă���B���̗�����[�߂邽�߁C�ȉ��̂悤�Ȋw�K��ƏK�Ƃ��čs���B
�ȉ��ł́CGPT�i�o�[�W����3�j�Ƃ̂��������̂܂܋L���B���߂ɁC�w�K�҂̍s���������Ƃ������C���̂��߂�GPT�ɂǂ̂悤�Ɏ�������C���̌��ʂ��ǂ��Ȃ�������������Ă���B
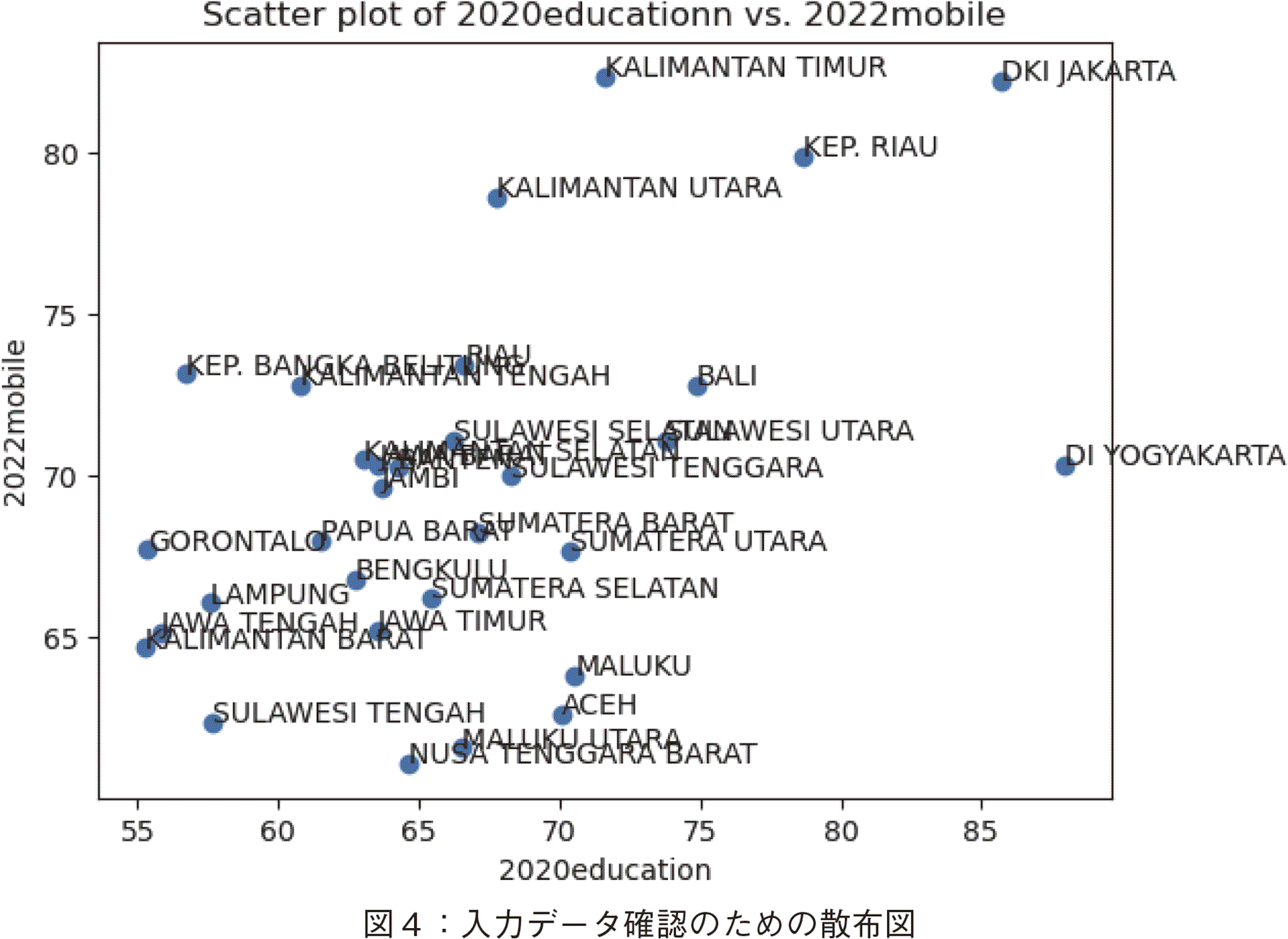
�@�@���̓f�[�^�m�F�̂��ߎU�z�}���v���b�g�������B
�@Q�F�uProvince, 2022sanitation, 2020education, 2022mobile, 2022gender�Ƃ����T�̕ϐ�������B���̂����̂Q�̕ϐ���I��ŁA�U�z�}���v���b�g����p�C�\���v���O�����������Ă��������B�e�f�[�^�ɂ́AProvince�̒l�����x���Ŏ������悤�ɂ������B�v
GPT���Ԃ��Ă��ꂽ�v���O�����ŗe�ՂɎU�z�}���v���b�g�ł����i�}�S�Q�Ɓj�B
�A�@���̓f�[�^�̕��U�����U�s������߂����B
�@Q�F�uProvince, 2022sanitation, 2020education, 2022mobile, 2022gender�Ƃ����T�̕ϐ�������B2020education,�@2022mobile�̂Q�̕ϐ��̕��U�����U�s������߂�p�C�\���v���O�����������Ă��������B�v
GPT�͓��̓f�[�^�Ƃ���array���g�����v���O������Ԃ����B���҂̓f�[�^�t���[���̃v���O��������]���Ă���̂ŁC�ȉ��̂悤�Ɏ����ύX�����B
�@Q�F�uProvince, 2022sanitation, 2020education, 2022mobile, 2022gender�Ƃ����T�̕ϐ�������B2020education,�@2022mobile�̂Q�̕ϐ��̕��U�����U�s������߂�p�C�\���v���O�����������Ă��������B�f�[�^��read_csv�i�j�œǂݍ���łق����B�v
���x�̓f�[�^�t���[�����g�����v���O�������Ԃ��ꂽ�BGPT�̉̃v���O�������y187�Łz
����ƁC���̃��C���p�[�g�́hcov_mat = np.cov�idf�m�mvar1, var2�n�n.T�j�h�@�ł������BT�͓]�u�s��̊��ł��邪�C�]�u�s������Ӗ���������Ȃ��̂ŁCGPT�Ɏ��₵���B
�@Q�F�u���U�����U�s������߂�Ƃ��A�Ȃ��ȉ��̂悤�ɓ]�u�s����Ƃ�̂ł����H
�@�@�@cov_mat = np.cov�idf�m�mvar1, var2�n�n.T�j�v
�@A�F���U�����U�s������߂�ꍇ�A�f�[�^�t���[���̍s���ϑ��l�A�ϐ��ɑΉ����܂��B�������Anp.cov���Ƀf�[�^�t���[����n���ꍇ�A�ϑ��l�A�s���ϐ��ɑΉ����邽�߁A�]�u�s�������ė�ƍs�̑Ή��𐳂�������K�v������܂��B�i�ȉ��C�����j
�@�@�@��L��GPT�̐����Ŗ��������̂ŁC��ɐi�ށB
�B�@�ŗL�x�N�g���ƌŗL�l���v�Z�������B
�@Q�F�u�����s�����͂��ČŗL�x�N�g���ƌŗL�l���v�Z����p�C�\���v���O�����������Ă��������v
�v���O���������Ɛ��������Ȍ��ʂ��Ԃ��ꂽ�̂ŁC�������āC���ɐi�ށB
�C�@�ŗL�l�̊�^�����v�Z�������B
�@Q�F�u�ŗL�l�̊�^�����v�Z����p�C�\���v���O�����������Ă��������v
�v���O���������Ɛ��������Ȍ��ʂ��Ԃ��ꖞ�����āC���ɐi�ށB
�D�@�听���������߂ĎU�z�}�Ɏ听�������v���b�g�������B
�@Q�F�u�Q�����f�[�^��PCA���s���A�e�f�[�^�̑�P�听���l�Ƒ�Q�听���l�����߂�v���O�������p�C�\���ŏ����Ă��������v
���╶���́u�Q�����f�[�^�v�̈Ӗ����C�Ԉ���ăf�[�^���Q�Ɖ��߂��ꂽ���ߕM�҂̈Ӑ}�ƈقȂ�v���O�������Ԃ��ꂽ�B�܂��C�hfrom sklearn.decomposition import PCA�h���C�u�������g���v���O�������Ԃ���C�M�҂͂��̏ꍇ�̓��̓f�[�^�`�����s���ƂȂ����B�����Ŏ�����ȉ��̂悤�ɕύX�����B
�@Q�F�u�f�[�^��read_csv�œǂݍ��݁A�f�[�^�ɑ���PCA���s���A�e�f�[�^�̑�P�听���l�Ƒ�Q�听���l�����߂�v���O�������p�C�\���ŏ����Ă��������v
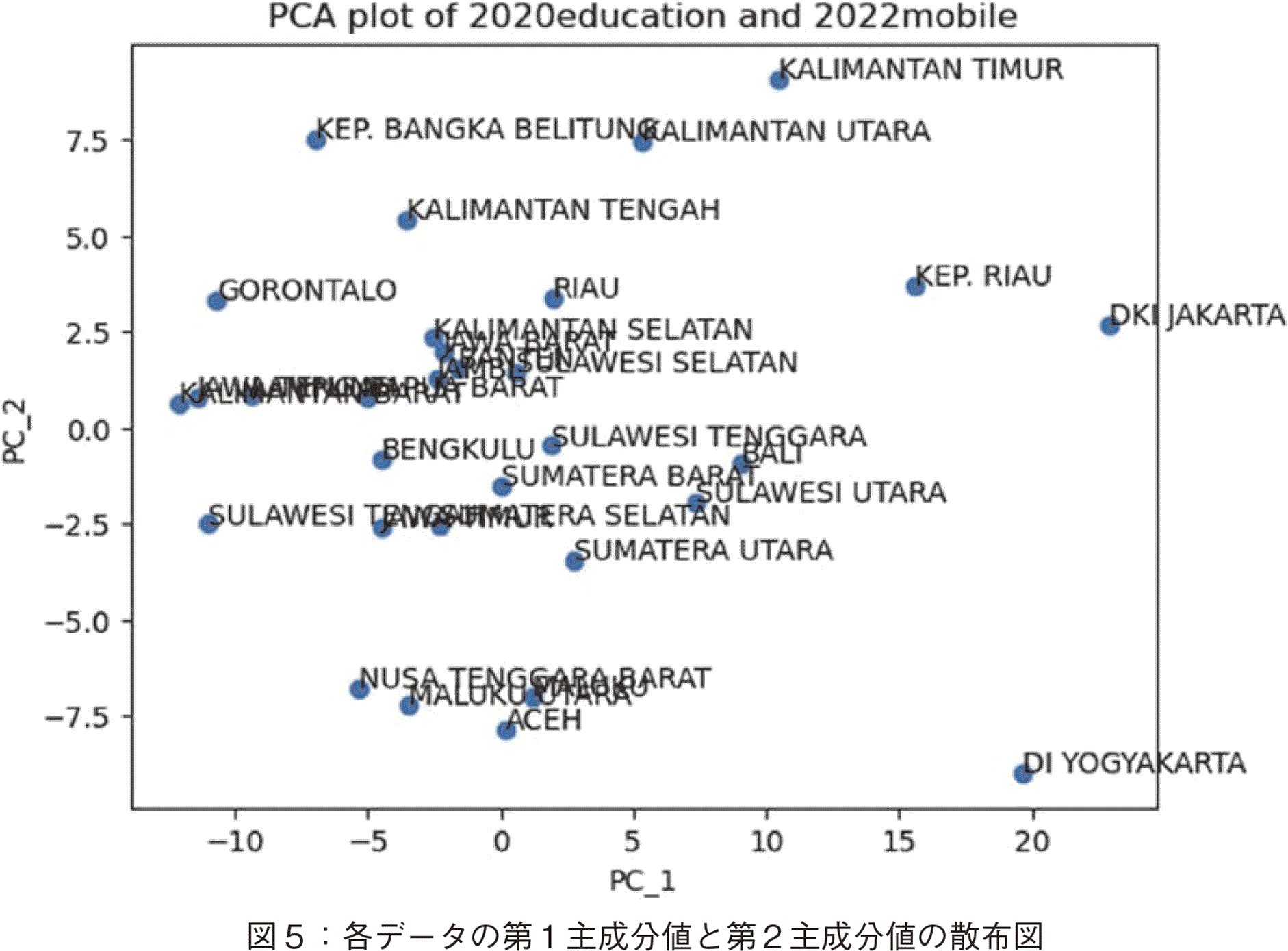
�Ԃ��ꂽ�v���O�����͓������B���ʂ̐��������m�F���邽�߂ɁC�e�f�[�^��PC_1��PC_2�ŎU�z�}��`�����i�}�T�Q�Ɓj�B�U�z�}�̃v���O�����́C�@�̖��GPT����v���O������Ԃ���Ă���̂ŁC����𗘗p�����B�}�T����C�������听���l������ꂽ���Ƃ��m�F�ł����B�����ŁC�听����������������v���O�������ȉ��̂悤�Ɏ��₵���B
�@Q�F�u�f�[�^��read_csv�œǂݍ��݁A�f�[�^�ɑ���PCA���s���A��P�听������ԐF�ŁA��Q�听������F�ŁA�f�[�^�̎U�z�}��ɕ`���v���O�������p�C�\���ŏ����Ă��������v
GPT�̃v���O�����ł́Cplt.scatter�idf.iloc�m:, 0�n, df.iloc�m:, 1�n �Ƃ����悤�ȑ����w������Ă����̂ŁC�f�[�^���{����ɍ����悤�ɁC�����Ńv���O������ύX�����B�v���O�����͓��������C�}�U�̂悤�ȈӐ}���Ȃ��}�ƂȂ����B�}�U����C���̓f�[�^�����H���ĕ��ϒl����̕����v���b�g���ׂ����ƁC�܂�C�f�[�^���ς��O�i���_�j�y188�Łz
�Ɉړ�����K�v�����邱�ƂɋC���t�����B���ς��v�Z����������߁C�ȉ��̂悤�Ɏ��₵���B
�@Q�F�u�p�C�\���Ńf�[�^�̕��ϒl�����߂�ɂ͂ǂ�����̂��H�v
GPT����̉ŁC numpy.mean�i�j���ł��邱�Ƃ�m��C�v���O�������C�����C�}�V�̃O���t��`�����B���ɁC��P�听�����Ƒ�Q�听���������������̂ŁA�f�[�^�͈͂��ɂ������ƍl�����B�����ŁC�ȉ��̎���������B
�@Q�F�u�p�C�\���ŎU�z�}�̃f�[�^�͈͂�-30����30�Ɏw�肷����@�́H�v
GPT����̉ŁCplt.xlim�i-30,30�j�̂悤�Ɏw�肷��ł��邱�Ƃ�m��C�v���O������ύX���C�}�W�̐}��`�����B�ȏ�B
�O�߂̎���̌��ʂ��āCGPT�𗘗p�������_�ɂ��f�[�^���͎�@�w�K�@�ɂ��čl�@����B
GPT�𗘗p���邱�ƂŁC�����ňꂩ��v���O�����������̂ɔ�r���ĒZ�����ԂŃv���O���~���O��i�߂邱�Ƃ��\�ƂȂ����B���ɁC�v���b�g�Ɋւ�����̃I�v�V�����w��Ɋւ��āC�T���v����ύX���邾���ŖړI�̃v���O�����邱�Ƃ��ł���_���D��Ă���B�s���������Ƃ̊T�O�����m�ɂȂ��Ă���Ƃ��ɁC�P���Ɋ���I�v�V�����C�����ȂǁC�}�j���A�����Q�Ƃ���킩��₢�ɑ��āCGPT�ɂ��̃v���O�����������Ă��炤���Ƃ͔��Ɍ��������߂�B
���́C�������m��Ȃ����G�ȊT�O�ɑ��āC�ǂ����₷�ׂ����ł���B���m�̊T�O�͑�ʂ���ƁC�i�P�j�v���O�����Ɋւ���m���C�Ɓi�Q�j�f�[�^���͂Ɋւ���m���ƂȂ�B�܂��C�p�C�\���v���O���~���O�ɂ��Ă̒m���K���Ɋւ���l�@���s���B�O�߂ŁC���ƂȂ����͈̂ȉ��̎����ɂ��Ăł������B
�y191�ŁzA�j�p�C�\���v���O�����ɂ����āCarray���g���������ɂ��邩�C�f�[�^�t���[�����g���������ɂ��邩�ŁCGPT���قȂ�\���̃v���O������Ԃ��B���̈Ⴂ��\�ߒm���Ƃ��ďK�����Ă��Ȃ��ƁC��ɐi�߂Ȃ��Ȃ�B
B�j�u���U�����U�s������߂�Ƃ��A�Ȃ��]�u�s���������̂��v�ɂ��Ă��C���C�u�����̎d�l�������Ȃ��Ă��邩��C�Ƃ������R�ł���B����̓}�j���A�����Q�Ƃ��ē��郌�x���̒m���ł���B�������C�����m��Ȃ��Ƃ��܂ł��v���O�����������Ȃ��Ƃ������������ԂɂȂ�B�s��v�Z�v���O�����쐬�ɂ����Ă��̖��œ����Ȃ����Ƃ������B
C�j���͂Ńv���O�������J�X�^�}�C�Y����K�v������BGPT���Ԃ��v���O�����̃f�[�^��ѕϐ��������C�����̕��̓P�[�X�̗��ϐ����ɒu���ł���v���O�����\�͂��K�v�Ƃ����B����͂ǂ̃v���O��������ł��悢�̂ŁC�v���O����������K�����Ă��Ȃ��ƁC�ł��Ȃ��\���������CGPT�����p�ł��郌�x���ɂȂ邽�߂ɂ́C�Œ���̃p�C�\���v���O���~���O���K���K�v�ł���B
���ɁC�f�[�^���͂ɂ�����m���̔������ł��邩�ۂ��Ƃ����ӏ����グ��B�����̖������ɂ́C���w�m���ƃv���O���~���O�m�����֘A���ĕK�v�ƂȂ�B
a�j�Q�����f�[�^�Ƃ������Ƃ��ɁC�u�Q�̗�̃f�[�^������v���Ƃ�������āC�u2�~2�s��v�̃f�[�^�����͂��ꂽ�ꍇ�C�Ƃ���GPT���v���O������Ԃ����B���҂́C�v���O�����̕Ԃ�l���f�[�^����32����ׂ��Ƃ���C�Q�����Ȃ��̂ŁC���r�ɋC���t�����B�ǂ����Ă��̂悤�ȊԈ�������ʂɂȂ����̂��C�A�u�_�N�V�����I���_���s�Ȃ����R�Ɏ���K�v������B�����̎���́u�Q�����f�[�^�v��������ꂽ���ƂɋC�Â��Ȃ��ƁC���R��������Ȃ��܂܂ƂȂ��Ă��܂��B
b�j�ŗL�x�N�g�������̂܂听�����Ƃ��ĕ`�����Ƃ���C�f�[�^�U�z�}�ƈقȂ�ꏊ�ɕ`���ꂽ�i�}�U�Q�Ɓj�B�����̈Ӑ}�ƈقȂ�v���b�g�ƂȂ����ꍇ�C���̗��R���l����K�v������B���̏ꍇ�́C���̓f�[�^�̕��ς����߁C���ς����_�ɂȂ�悤�ɕ��s�ړ�����K�v�����邩��ł���B����ɋC���t�����ۂ��́C�w�K�҂��A�u�_�N�V�����I���_�ŁC���̗��R�Ɏv�����邩�ۂ��Ɉˑ�����B���Ɂu�ԈႢ�₷�����ӂ��ׂ��_�v�Ƃ��āCWEB�̂ǂ����Ő�B���R�����g���Ă���ꍇ�C��������p����GPT���w�E���Ă����\��������B���������C��㈐��_�ߒ��̒��̃~�b�V���O�����N�ƂȂ����A�u�_�N�V�����ɑ��āCGPT�ɏ��Ɏ�������鎿��͂����シ�邱�Ƃ��]�܂��B
c�j�f�[�^�̎U�z�}��Ɏ听����������悤�ɕ`�������ꍇ�C�Q�ϐ��̒�`��̕����ɂ��Ȃ��ƒ������Ȃ��B�������Ȃ��Ƃ�����������C���̗��R���A�u�_�N�V�������邱�Ƃ́C�ȒP�ɂł��Ȃ��\���������B�Ⴆ�uQ�FPCA�Ŏ听���P�Ǝ听���Q�̎���`�����̂ł����C�������܂���B���́C�听�����݂͌��ɒ�������ƏK���܂����B���̃p�C�\���v���O�������Ԉ���Ă���̂ł��傤���H�v�Ǝ��₵�āCGPT���u���̒�`��͈̔͂��ɂ���K�v������܂��v�Ɠ����邱�Ƃ������\�ɂȂ邩�C�M�҂͑����\�ƂȂ�Ɨ\������B
�����̎��Ⴉ��C��ʓI�ȃf�[�^���͂ɖ{��@��K�������ꍇ�ɂ��čl�@��i�߂�B
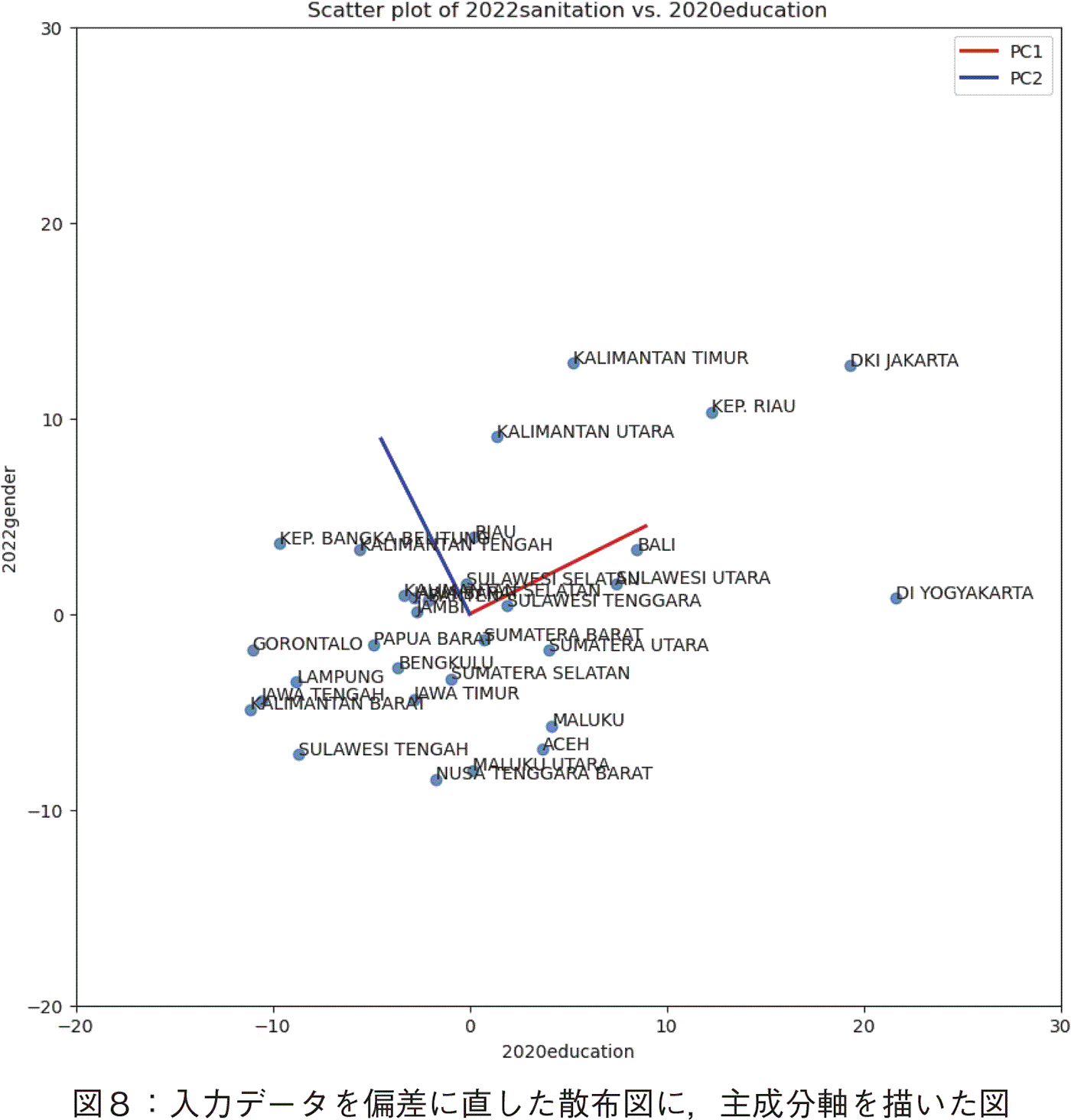
�d�v�Ȃ��Ƃ́C���߂ɍ쐬���鉉㈐��_�ߒ��̃_�C�A�O�����C���Ă̍쐬�ł���B����͋��t�����Ă���邱�ƂɑΉ����Ă���i�}�R�Q�Ɓj�B�w�K�҂͂��̃_�C�A�O�����ɏ]���CUnknown�ɓ��B����܂ʼn�㈐��_���s���B��Q�߂Ŏ������C���͑���������߂̉�㈐��_���y192�Łz ���Ɨގ����Ă��邪�C�قȂ�_�͈ȉ��̂悤�ɂ܂Ƃ߂���
�i�P�j�O���t�E�v���b�g�̏d�v���̑����F�@�e��㈐��_�̌��ʂ��v���b�g�ʼn������邱�ƂŁC���̉�㈌��ʂ����ł���B�܂��C�v���b�g���邱�ƂŁC���̊T�O�ɑ��闝�����[�܂�B���l���������邾���ł́C���̂悤�ɗ����͐[�܂�Ȃ��B
�i�Q�jGPT�Ƃ��������nAI�̑��݂̏o���F�@��L�i�P�j���\�Ƃ���@�\�́CGPT���v���O������Ԃ��Ă����@�\�ł���B�����̂��߂̃v���O���~���O���e�ՂɂȂ����̂ŁC������p�ɂɍs����悤�ɂȂ����B����͏]���̃f�[�^���͕��@�����{�I�ɕς���B
�@�@�@�@����͗Ⴆ��ƁC��Ђ̏d���ɑ��ăC���e���W�F���g�鏑�����āC�f�[�^���͂��T�|�[�g���Ă����悤�ȑ��݂ł���B�Ⴆ�C�d���́u���̃f�[�^�̂������10���̃f�[�^�Ɍ��肵�āCPCA�����ăv���b�g���Ăق����v�i�Ώۃf�[�^�̌���j�C�u�������k�A���S���Y����PCA����UMAP�ɕς��Ă���Ă݂āC���̌��ʂ��v���b�g���Ăق����v�i�A���S���Y���̕ύX�j�C�uShapley�l���v�Z������CShapley�l���g���āC�N���X�^�����O���ăN���X�^�[���Ƃ̕ϐ��̕��ϒl�����߂Ăق����v�i���͎�@�̍��킹�Z�j�ƁC�f�[�^�A�i���X�g�Ɉ˗����邩�̂悤�ɁC���X�ƌ������������͌��ʂ����N�G�X�g����̂ɗގ����Ă���B�]���́C�����Ńv���O������g�ރR�X�g�������̂Ŏ�������ł��������ʓI�ȕ��͂��CGPT�̏o���ɂ��C���Ȃ��R�X�g�Ŏ����\�ƂȂ����B�w�K�V�X�e�����CGPT�����p����悤�ɕϊv����K�v������B
�i�R�j�z�肵�Ȃ����ʂ̏ꍇ�̗��R�����ɂ�����GPT�̊��p�F�@�z�肵�����ʂƈقȂ錋�ʂ��ł��ꍇ�C���̗��R���A�u�_�N�V��������B���̃A�u�_�N�V�����̍ۂɁCGPT�Ɏ��₷�邱�ƂŁC���R��������\��������B���̉����̌��́C�v���b�g�v���O�����̐������̌�������ʂɓ���B�v���b�g�̏ꍇ�́C�ڂł�����x�m�F�ł��邪�C���̂悤�ȏꍇ�̊Ԉ�������R�͔��f���������ł���B
GPT�͓����ړI�̃v���O�����Ƃ��āC�����̈قȂ�v���O������Ԃ��B�Ⴆ�C�p�C�\����array���g�����f�[�^�t���[����p���邩�ŕ��@�͈قȂ邪�����v�Z�͉\�ł���B�܂��C�������������̃��C�u�����Ŏ����ł���ꍇ�C���p���郉�C�u�����Ɉˑ����ăf�[�^�`���͈قȂ邾�낤�B�w�K�҂͕����̃v���O��������œK�Ȃ��̂�I������ہC�P�����ƌo�ϐ����d�����ׂ��ł���B����͈�ʓI�ȃA�u�_�N�V�����ɂ����鉼���I���̏ꍇ�Ɠ��l�ł���B�P���ȉ����قǁC����������I�Ƀe�X�g����̂ɔ�p�⎞�Ԃ�v�l��G�l���M�[���ߖ�ł��邩��C�P���ȉ�����I�����ׂ��ł���B���w�҃W���[�W�E�|���A�iGeorge Pólya�j�m22�n���C�������������̂ɁC�m���Ă��邩��ƌ����āC����e�N�j�b�N����g���ĉ��������C�ȒP�ɉ�������@��I�����ׂ��ł���C�ƌ����Ă���m23�n�B���̍œK�I�����ł���\�̗͂{�����C�w�K�V�X�e���̉ۑ�ƌ�����B
�f�[�^���͎�@�w�K�V�X�e���Ƃ��āC�l�@�����Ă������C�ȉ��ł̓f�[�^���͎�@���w�K�������̃f�[�^�Ńf�[�^���͂��s�����Ƃ����Ƃ����ꍇ�C��L�̉�㈐��_�ߒ��̈ʒu�Â��͂ǂ��Ȃ�̂��l�@����B�A�u�_�N�V�����ƋA�[�̗Z���ɂ��m�������̎����������҂���Ă��Ă���m16�n�B�f�[�^���̖͂ړI��m�������Ƃ���Ȃ�C�������V�X�e���ɕ���ăf�[�^���͂��邱�ƂŐl�Ԃ������I�ɒm���������邱�Ƃ����҂ł���ł��낤�BRay�ɂ��ƁC�m�����W�̃v���Z�X�́C�A�u�_�N�V��������㈁��������C���_�N�V�����i�A�[�j���A�u�_�N�V�����y193�Łz ���i�ȉ����ꂪ�����j�̃X�p�C�����ł���m16, 24�n�B�����Ř_���Ă���m���Ƃ́C�Ȋw�ɂ�����m�������ł���C�Ⴆ�C�u���Z���Ǝ҂̂ق��������������v�Ƃ��������𗧂āC��㈂ɂ��\���⌟���s���C�������s���C���ʂ��ώ@���āC���ɋA�[�Ƃ��āC�����̎��ۊԂɐ��������ʉ����i�Ⴆ�C�u������������l�̂ق��������������v�j�����C��O�Ƃ��āu�g�ѓd�b�����Ɏg����l�͑��̐l�ɔ�r���ċ����������v��Ⴆ�Δ������C����ɑ��čĂуA�u�_�N�V�����ɂ���čl����C�Ƃ����X�p�C�����ł���B
�{�e�̋c�_�̑Ώۂ́C��L�X�p�C�����̉�㈂ɂ�鉼�����̕����ł���B�f�[�^���͂������鋳��҂̗���Ƃ��āC���̉�㈉ߒ��𐳂������������邱�Ƃ����`�ƍl���邩��ł���BGPT�̊��p�͖]�܂����B�����C�Z�L�����e�B�I��肩��C�������ẴA�u�_�N�V������A�[��GPT���g�p���邱�Ƃ͍���c�_�����ׂ��ۑ�ƍl���邩��ł���B�͂ꂽ�Z�p�ł���f�[�^���͎�@�ɂ��Ă�GPT�ւ̎���ɂ́C�V�����m���͊܂܂�Ă��Ȃ��̂ŁC���Ȃ��ƍl����B
�{�e�ł́C���_�ɂ��f�[�^���͎�@�̊w�K��GPT�ʼn���������@�ɂ��Ę_�����B�M�҂����N���������H���Ă���o�όo�c���w�̊w�K��@��㈐��_�@�Ƃ̈Ⴂ�́C�ȉ��̂R�ł���B�i�P�j��㈐��_�̊e��㈉ߒ��ɂ�����v���b�g�̏d�v���̑����B����̓f�[�^���͂̓����ł���C�p�ɂɉ����������ق������̊T�O�ɑ��闝�����[�܂�B�i�Q�jGPT�Ƃ���AI�̑��݂̏o���BGPT�������v���O�������̃v���O������Ԃ��Ă����̂ŁC�f�[�^��������Ԃ��������ɕp�ɂɍs����悤�ɂȂ����B����͏]���̃f�[�^���͕��@�̊w�K�@�����{�I�ɕς���ł��낤�B�i�R�j�z�肵�Ȃ����ʂ̏ꍇ�̗��R�����ɂ�����GPT�̊��p�B�w�K�҂͎������Ԉ�������R���A�u�_�N�V�������悤�Ƃ���ہCGPT�Ɏ��₷�邱�Ƃŕ�����\��������B
�{�e�ŏq�ׂ����_�ɂ��f�[�^���͎�@�̊w�K�V�X�e�����\�z����ꍇ�C���́C�w�K�Ҏ��g���m��Ȃ����G�ȊT�O�ɑ��āC�ǂ����₷�ׂ����ł���B���m�̊T�O�͑�ʂ���ƁC�i�P�j�v���O�����Ɋւ���m���C�Ɓi�Q�j�f�[�^���͂Ɋւ���m���ƂȂ�B�z�肵�Ȃ����ʂ��ǂ����߂���̂��C�ǂ̂悤��GPT�Ɏ��₷��Ƃ悢���A�w�K�҂̂���܂ł̒m���ƃX�L���ɌW���Ă���B
�p�[�X�ɂ��ƁC�l�Ԃɂ͖{���u��������������\�́v��������Ă���B����āC�l�Ԃ̐��_�͍l����ꂤ�邠���鉼���̒�����C����L����̐����ɂ���Ă����Ƃ��������������l�����Ă邱�Ƃ��ł���C�Ƃ���m15�n�B�f�[�^���͎�@�w�K�ߒ��ɂ����Ă��C���ĂƈقȂ錋�ʂ��ł��ꍇ�C���̊Ԉ�������R�邽�߁C�A�u�_�N�V�����ɂ�艼����I�������Ƃɂ����āC�l�Ԃ͋@�B�����n���I�ɉ����I�����������BGPT�̊��p�͂��̗L����̐����̌������ɖ𗧂B��l�B�̏W���m����ɁC�w�K�҂��悭���G���[����𑽐��~�ς��邱�ƂŁCGPT�͑����̉�������邱�Ƃ��\�ƂȂ�B���ꂽ���݂̒�����C�������̖��̌��ۂɂ����āC�ł����ɂ��Ȃ������������鉼����I������X�L�����C�w�K�҂͂����Ȃ��Ă�GPT�����p���邱�Ƃ͂ł��Ȃ��B�A�u�_�N�V�����ɂ����ĉ�X�l�Ԃ͋@�B�����n���I�ł��鉼���I�����\�Ƃ���悤�ɁC��ɃX�L�������}��ׂ��ł��낤�B
�y194�Łz�m�P�n �T�����m�o�ϕҏW���C�gChatGPT �d���p�v���C�h�T�����m�o�� 2023�N4/22���C2023.
�m�Q�n �Ǔc�`�a�C�g��Ë��番��ɂ���������� e ���[�j���O�����C�h ���S�H�w�Cvol. 62, no. 2, pp. 87-93, 2023.
�m�R�n P. Stanworth, and Y. Shirota, �gReview of the "WebHow2SolveIt" Website,�h Gakushuin Economics Papers, vol. 50, no. 1, pp. 1-18, 2013
�m�S�n Y. Shirota, T. Hashimoto, and S. Suzuki, "Knowledge Visualization of Reasoning for Financial Mathematics with Statistical Theorems." pp. 132-143.
�m�T�n Y. Shirota, T. Hashimoto, and B. Chakraborty, "Deductive Reasoning for Joint Distribution Probability in Simple Topic Model." pp. 622-625.
�m�U�n Y. Shirota, T. Hashimoto, and B. Chakraborty, �gVisualization of Deductive Reasoning for Joint Distribution Probability in Simple Topic Model,�h Information Engineering Express, vol. 3, no. 1, pp. 1-8, 2017.
�m�V�n Y. Shirota, and T. Hashimoto, "Plausible deductive reasoning plan for business mathematics learners." pp. 5-8.
�m�W�n Y. Shirota, and T. Hashimoto, �gLearning Material Development Tool to Support Deductive Inference While Solving Business Mathematics Problems,�h Gakushuin Economic Papers, vol. 48, no. 4, pp. 303-311, 2012.
�m�X�n Y. Shirota, T. Hashimoto, and T. Kuboyama, "A concept model for solving bond mathematics problems," Information Modelling and Knowledge Bases XXIII, pp. 271-286: IOS Press, 2012.
�m10�n ���{���q�Cand ���c�R�����C�g�����w�ɂ������@�v�������o�̂��߂̎x���V�X�e���̒�āC�h ���{�o�c���w��Cvol. 33, pp. 43-56, 2012.
�m11�n ���c�R�����C�g�o�c���w����@�ɂ����鉉㈐��_�Ɋւ���l�@�C�h �{�K�@��{�S�Z�_�W�Cvol. 49, no. 2, pp. 85-98, 2012.
�m12�n ���c�R�����Cand ���{���q�C�g�o�c���w�������@�̂��߂̉�㈐��_�x�����ލ쐬�c�[���C�h �{�K�@��{�S�Z�_�W�Cvol. 48, no. 4, pp. 303-311, 2012.
�m13�n Y. Shirota, T. Hashimoto, and P. Stanworth, "Knowledge Visualization of the Deductive Reasoning for Word Problems in Mathematical Economics." pp. 117-131.
�m14�n �Đ��T��C�A�u�_�N�V�����F�����Ɣ����̘_���F�������[�C2007.
�m15�n �Đ��T��C�p�[�X�̋L���w�F�������[�C1981.
�m16�n ��㍎���C�g�A�u�_�N�V�����ƃC���_�N�V�����i<���W>�_���Ɋ�Â����_�����̓����j�C�h �l�H�m�\�Cvol. 25, no. 3, pp. 389-399, 2010.
�m17�n ���c�R�����C�Y�߂�w���̂��߂̌o�ρE�o�c���w����F�R�̉�@�e�N�j�b�N�Ő��w�A�����M�[������!�F�����o�ŁC2009.
�m18�n ���c�R�����C�g��㈐��_�@�ɂ��u���b�N= �V���[���Y�������̓��o�C�h �{�K�@��{�S�Z�_�W�Cvol. 50, no. 3, pp. 43-55, 2013.
�m19�n C. M. Bishop, and N. M. Nasrabadi, Pattern recognition and machine learning: Springer, 2006.
�m20�n S. Theodoridis, and K. Koutroumbas, Pattern recognition: Elsevier, 2006.
�m21�n �e�r���CPython �f�[�^�T�C�G���X�n���h�u�b�N�FJupyter, NumPy, pandas, Matplotlib, scikit-learn ���g�����f�[�^���́C�@�B�w�K�C2018.
�y195�Łz�m22�n G. Polya, Mathematics and plausible reasoning, Volume 1: Induction and analogy in mathematics: Princeton University Press, 1954.
�m23�n G. Polya, Mathematics and plausible reasoning, Volume 1: Induction and analogy in mathematics: Princeton University Press, 2020.
�m24�n O. Ray, �gHybrid abductive inductive learning,�h Department of Computing, Imperial College London, UK, 2005.