
東日本震災に対するタイランド国民のSNSでの反応比較
成果紹介ビデオ
日本語
English
ไทย
ビデオの主な内容
分析の手順
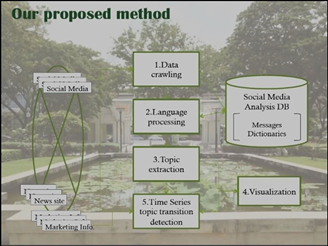
- Data crawling:データ収集
- Language processing:言語処理
- Topic extraction:トピックの抽出
- Time Series topic transition detection:トピックの変化を時系列で分析する
- Visualization:可視化
①Data crawling:データ収集

タイのwww. pantip.com、www. sanook.com、www. kapook.comおよび日本の価格.comの掲示板、NPO法人(SAVE IWATE)のBlogのログから書き込み情報を取得する。タイのソーシャルメディアからは三ヶ月間2001件のメッセージを取得した。
②Language processing:言語処理

形態素解析ソフトを用いて単語の分割・品詞判別などの言語処理を行う。タイ語は声調を用いる言語(tonal language)であるため、曖昧さの問題があり、言語処理は極めて難しい。言語処理にはタイ語形態素解析ソフトSwath(Smart Word Analysis for THai) および日本語形態素解析ソフトMeCab(和布蕪)を用いた。
③Topic extraction:トピックの抽出

単語と単語の間のつながりを分析し、そのクラスターからその書き込みのトピックを決める。
・トピックの抽出の方法
形態素解析の結果に対してRIDF残差逆文書頻度 ( IDFは単語重要性を判定するための指標であり、その単語が出現する文書数が少ないほど、その単語が出現する文書にとっては有用であることを示す。 RIDFはそれにポアッソン分布による誤差の推定を加味したもの)の値によって単語の重要性を決める。

([ ]内にRIDF値が記されている。数値が高いほど重要性が高い。)
LSA(潜在的意味解析Latent Semantic Analysis:単語の集合体からトピックを解析する作業)、LDA(潜在的ディリクレ配分法Latent Dirichlet Allocation:潜在的意味解析をディリクレ配分(事象の生起確率の分布)によって補正する方法)によってトピックを抽出する。

日本とタイの結果の比較
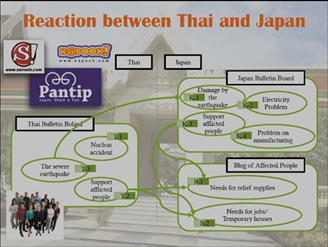
タイ語の書き込みについてはトピックをT1原発事故、T2被災者援助、T3巨大地震文類し、日本の掲示板の書き込みのトピックをK1地震の被害、 K2電力問題、K3被災者援助、K4産業の問題に分類し、被災者のブログのトピックをB1援助物資の必要性、B2仕事/仮設住宅の必要性に分類した。
④Time Series topic transition detection:トピックの変化を時系列で分析する。
一日ごとの各トピック数をカウントし、時系列に並べる。
⑤Visualization:可視化
グラフ等によって結果を見やすくする。
